Как я делаю говорящее фото через ИИ (а главное, где)

Еще пять лет назад создать видео, где человек на фотографии двигает губами, моргает и поворачивает голову в такт реальному голосу, стоило сотни тысяч рублей и требовало целой команды специалистов по компьютерной графике. Сегодня та же задача решается в браузере за несколько минут: нейросеть самостоятельно анализирует ключевые точки лица, выстраивает мимику и синхронизирует артикуляцию с любой аудиодорожкой. Технология стала доступной, а результат — убедительным даже для профессионального взгляда.
В этой статье я разбираю несколько ключевых тем. Во-первых, почему технология говорящих портретов вышла за пределы киностудий и стала массовой. Во-вторых, какие платформы позволяют сделать фото говорящим — нейросеть справится с задачей быстро и без глубоких технических знаний. В-третьих, что нужно учесть при подготовке исходного изображения — этот пункт недооценивают чаще всего. В-четвертых, как правильно работать со звуком и добиться идеальной синхронизации. И наконец, как выбрать оптимальный сервис с помощью наглядной сравнительной таблицы.
Почему говорящие портреты перестали быть привилегией киностудий
Ключевой прорыв произошел в 2018–2021 годах, когда исследовательские группы выпустили несколько открытых архитектур — Wav2Lip, First Order Motion Model и SadTalker. Эти модели доказали, что задачу анимации лица можно решать без дорогостоящего оборудования для захвата движений. Алгоритм изучал, как именно двигаются губы, щеки и брови при произнесении каждого звука, после чего применял эти паттерны к любому статичному портрету. Результат оказался настолько убедительным, что технология начала стремительно проникать в коммерческие продукты.
Современный принцип работы выглядит следующим образом. Модель получает на вход два источника: исходное изображение — статичный портрет — и аудиофайл с речью или синтезированным голосом. Нейросеть определяет ключевые точки лица: десятки маркеров на губах, веках, бровях, скулах и контуре лица. Затем алгоритм генерации кадров сопоставляет положение этих точек с каждой фонемой в аудиосигнале. На выходе получается видеоряд, где синхронизация губ с произносимыми словами выглядит органично, а лицо дополнительно оживляется морганием, изменением наклона головы и тонкими эмоциональными движениями.
Здесь важно понимать связь технологии говорящих фото с понятием дипфейк. Оба направления используют схожие алгоритмы анализа и анимации лиц, однако различаются по целям и области применения. Дипфейк традиционно ассоциируется с манипуляцией чужой внешностью в мошеннических или политических целях, тогда как анимация портрета в большинстве случаев применяется для совершенно легитимных задач: образования, маркетинга, персонализированных поздравлений и создания видеоаватаров для корпоративных презентаций. Именно поэтому крупные платформы обязательно требуют подтверждения прав на загружаемое изображение.
Что именно сделало технологию массовой в 2024–2026 годах? Я выделю четыре ключевых фактора:
- Рост мощностей облачных серверов: обработка в облаке теперь занимает секунды, а не часы, и не требует мощного локального железа от пользователя.
- Появление открытых моделей — которые дали толчок волне коммерческих сервисов и снизили барьер входа для разработчиков.
- Взрывной спрос на персонализированный видеоконтент в соцсетях, рекламе и онлайн-образовании.
- Снижение стоимости: сегодня говорящее фото ИИ бесплатно доступно в пробном формате как минимум на нескольких популярных платформах.
Важную роль сыграло и параллельное развитие синтеза речи (TTS). Современные TTS-движки настолько точно воспроизводят человеческие интонации, паузы и эмоциональный окрас, что в паре с качественным липсинком создают полноценный эффект живого человека в кадре. Именно поэтому технологию активно используют для создания ИИ-дикторов и виртуальных ведущих — персонажей, которые произносят любой текст с нужной интонацией, не требуя реального человека перед камерой.
Что умеют лучшие платформы: обзор сервисов для создания говорящего видео
- MashaGPT — русскоязычный чат-бот на базе GPT-4o с входом через Яндекс, VK и Google.
- Study AI — платформа для оживления фотографий и анимации портретов с возможностью редактировать движения, мимику и эмоции.
- Kling — нейросеть с реалистичной анимацией лиц, синхронизацией губ и виртуальной примеркой одежды.
- Apihost — узкоспециализированный платный сервис для бизнеса и маркетплейсов, превращающий фотографию и текстовый промпт в готовый MP4-ролик длиной до 15 секунд с аудиодорожкой.
- SmartBuddy — единое рабочее пространство с доступом к 100+ нейросетям, генерацией диаграмм, бизнес-планов и открытым API.
- GPTunneL — инструмент оживления фотографий на базе нейросети Seedance с анимацией мимики и движений по текстовому описанию.
- GoGPT — агрегатор 20+ топовых нейросетей (ChatGPT, Claude, Veo, Sora, Midjourney) в одном окне с системой GoCoin и переносом баланса на следующий месяц.
- Flyvi — российский ИИ-редактор с генерацией видео до 30 секунд, поддержкой нескольких референсных кадров и полностью русскоязычным промптом.
- ruGPT — сервис с аудиторией 7+ млн пользователей, генерирующий видео с озвучкой из текста или фото за несколько секунд без редактора.
- Chad AI — продукт с доступом к Veo 3.1 от Google с кинематографическим качеством, синхронизацией губ и встроенным звуком.
- AISearch — ИИ-ассистент с браузерным расширением для Chrome, адаптирующий тексты под индивидуальный стиль пользователя на любом сайте.
1. MashaGPT
Агрегатор нейросетей с аудиторией более 1 миллиона пользователей, который закрывает сразу все потребности в ИИ-инструментах: от написания текстов и кода до генерации изображений, видео и музыки. Сервис работает на всех популярных платформах, включая мобильные приложения и десктопные версии для Windows и macOS, что делает его одним из самых доступных решений для российского пользователя. Единая подписка открывает доступ ко всему инструментарию сразу, без необходимости оплачивать каждый сервис отдельно.

- Тип поддерживаемых файлов: jpeg; png; pdf; docx; txt; mp4, mp3.
- Функции: доступ к 50+ нейросетям в едином интерфейсе; генерация изображений через; генерация видео через; создание музыки; работа с файлами и кодом.
Плюсы:
- самый широкий набор модальностей среди российских агрегаторов — текст, фото, видео и аудио под одной подпиской;
- приложения для всех платформ включая Windows и macOS;
- бесплатный старт.
Минусы:
- бесплатный лимит всего 12 сообщений в 3 часа;
- доступ к топовым моделям только на платных тарифах;
- большой выбор моделей может дезориентировать новичка.
2. Study AI
Многофункциональная ИИ-платформа с акцентом на работу с медиаконтентом, в том числе с функцией оживления фотографий. Инструмент анимации изображений позволяет буквально сделать фото говорящим: персонаж на снимке начинает двигаться, моргать, поворачивать голову. Платформа сочетает текстовые, визуальные и видеоинструменты в едином интерфейсе на русском языке. Удобна для контент-мейкеров, которые хотят работать с современными зарубежными моделями.
- Тип поддерживаемых файлов: jpeg; png; gif; mp4.
- Функции: оживление и анимация фотографий; генерация видео из изображений; доступ к моделям kling ai; работа с текстом; создание ботов.
Плюсы:
- поддержка анимации портретов с реалистичным движением;
- объединение нескольких ИИ-инструментов в одном месте;
- русскоязычный интерфейс.
Минусы:
- ограниченная длина генерируемых роликов;
- интерфейс может быть перегружен для новичка.
3. Kling
Шлюз к одной из самых мощных видеонейросетей для анимации изображений. Сервис специализируется на генерации кадров с высокой реалистичностью: модель умеет воспроизводить тонкие движения — эффект наклона головы, мимику, моргание — создавая убедительную иллюзию живого человека на фото. Kling поддерживает синхронизацию губ с речью и виртуальную примерку одежды. Платформа ориентирована на профессиональных создателей контента, которым важно кинематографическое качество выходного видео.

- Тип поддерживаемых файлов: jpeg; png; mp4.
- Функции: анимация фото с реалистичным движением; синхронизация губ с аудио; виртуальная примерка одежды; генерация видео по тексту и изображению; управление движением камеры.
Плюсы:
- высокое качество анимации лица и тела; синхронизация речи с движением губ;
- широкий контроль над сценой и движениями персонажа.
Минусы:
- генерация видео может занимать некоторое время;
- ограниченная длина видео на базовых тарифах.
4. Apihost
Apihost AI Video Generator — специализированный платный сервис для бизнеса и маркетплейсов, превращающий фото и текстовый промпт в готовый MP4-ролик длиной до 15 секунд. Загруженное изображение становится стартовым кадром, а нейросеть достраивает анимацию, движение и звуковое сопровождение на основе вашего описания. Прозрачная тарификация — 30 ₽ за секунду видео — делает сервис предсказуемым по затратам. Особенно востребован для карточек товаров на Wildberries и Ozon, где динамичный контент увеличивает кликабельность. Рендеринг занимает 1–2 минуты, результат сразу готов к публикации.

- Тип поддерживаемых файлов: jpeg; png; mp4.
- Функции: генерация видео из фото и текста; создание аудиодорожки по промпту; экспорт в mp4; адаптация под форматы маркетплейсов и соцсетей.
Плюсы:
- прозрачная посекундная тарификация;
- автоматическая генерация звука;
- быстрая подготовка контента;
- не требует навыков монтажа.
Минусы:
- нет бесплатного режима;
- максимальная длина ролика — 15 секунд;
- нет встроенного редактора для доработки результата.
5. SmartBuddy
Многофункциональное рабочее пространство на базе ИИ, объединяющее более 100 нейросетей через единый API без географических блокировок. Сервис выходит далеко за рамки обычного чата: здесь можно создавать диаграммы, бизнес-планы, генерировать изображения, видео и музыку, работать с файлами и строить аналитические отчеты. Встроенный AI Vision распознает объекты и текст с изображений, а инструмент бизнес-планирования проверяет идею по 25 параметрам. Уникальное преимущество — собственный открытый API для встраивания нейросетей в сторонние проекты.
- Тип поддерживаемых файлов: jpeg; png; pdf; docx; xlsx; txt; mp4; mp3.
- Функции: доступ к 100+ нейросетям; генерация изображений, видео и музыки; создание диаграмм и бизнес-планов; работа с файлами и их анализ; поиск в интернете; api для разработчиков.
Плюсы:
- широкий охват инструментов в одном интерфейсе;
- открытый API для интеграций;
- встроенный анализ бизнес-идей по 25 критериям.
Минусы:
- избыточный функционал для простых задач;
- стоимость зависит от выбранных моделей;
- порог входа для новичков выше среднего.
6. GPTunneL
Специализированный инструмент внутри экосистемы GPTunneL для оживления статичных фотографий с помощью нейросети Seedance. Загружаете снимок, описываете желаемое движение — и получаете видеоролик длиной до 6 секунд, в котором персонаж начинает двигаться естественным образом. Возможности модели охватывают движение глаз, мимику, а также эффект наклона головы, что создает иллюзию живого кадра из обычной фотографии. Инструмент встроен в более широкую платформу GPTunneL, предоставляющую доступ к различным ИИ-приложениям. Подходит для быстрого создания анимированного контента из архивных или портретных фото.
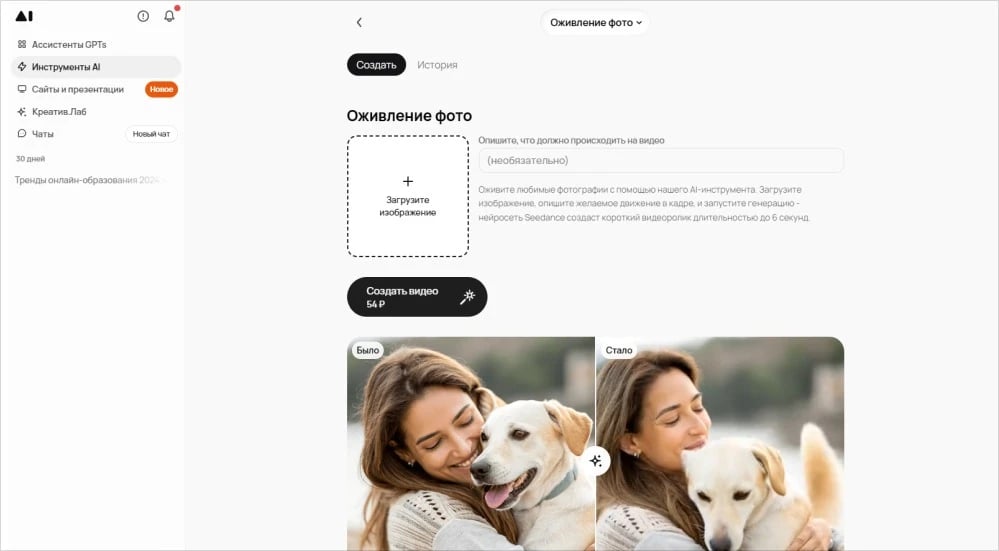
- Тип поддерживаемых файлов: jpeg; png.
- Функции: оживление фотографий; описание желаемого движения в текстовом промпте; генерация видео длиной до 6 секунд; доступ к другим ИИ-приложениям платформы GPTunneL.
Плюсы:
- простой сценарий использования — фото плюс описание;
- натуральная анимация мимики и движений;
- не требует специальных навыков; интеграция в экосистему с другими ии-инструментами.
Минусы:
- максимальная длина клипа всего 6 секунд;
- ограниченный контроль над параметрами анимации;
- нет расширенных настроек камеры или сцены.
7. GoGPT
Агрегатор нейросетей, объединяющий в одном интерфейсе ChatGPT, Claude, Grok, DeepSeek, Midjourney, Veo, Sora, Flux, Kling и десятки других моделей, доступный в России без VPN и иностранной карты. Сервис предлагает не просто чат, а полноценную экосистему: управление контекстом, шаблоны запросов, FaceSwap, генерацию изображений и видео, а также Telegram-бот для работы на ходу. Уникальна система GoCoin — внутренняя валюта с прозрачной стоимостью каждого запроса и переносом остатка на следующий месяц. Есть партнерская программа и API для разработчиков. Бесплатный тариф позволяет делать до 10 запросов в день.

- Тип поддерживаемых файлов: jpeg; png; pdf; docx; txt; ссылки; youtube-видео.
- Функции: доступ к 20+ нейросетям; генерация изображений и видео; обучение модели на своих фото; анализ файлов и ссылок.
Плюсы:
- широкий выбор топовых нейросетей в одном окне;
- прозрачный учет расходов через GoCoin;
- перенос неиспользованных коинов на следующий период.
Минусы:
- бесплатный лимит быстро исчерпывается;
- видео и изображения доступны преимущественно на платных тарифах;
- часть моделей находится в статусе «скоро».
8. Flyvi
Российский онлайн-редактор со встроенным ИИ-генератором видео, заточенный под нужды бизнеса, SMM и e-commerce. Платформа позволяет не просто анимировать фото, но и задавать стартовый и финальный кадр, продолжать существующие ролики и создавать клипы по нескольким референсам одновременно. Генерация кадров происходит за несколько минут, а максимальная длина ролика достигает 30 секунд — больше, чем у большинства аналогов. Весь интерфейс и промпт-система полностью на русском языке, что снимает языковой барьер. Дополнительно доступны инструменты ИИ-мастерской: Nano Banana, замена фона, удаление объектов.

- Тип поддерживаемых файлов: jpeg; png; mp4.
- Функции: генерация видео из фото и текста; задание стартового и финального кадра; продолжение существующего ролика; генерация по нескольким референсам; добавление звука через промпт; режим pro для сложных сюжетов.
Плюсы:
- максимальная длина ролика до 30 секунд;
- полностью русскоязычный интерфейс и промпт;
- поддержка нескольких референсных кадров;
- дополнительные ИИ-инструменты для редактирования фото.
Минусы:
- нет полноценного встроенного видеоредактора;
- часть функций доступна только на платных тарифах;
- результат зависит от качества исходного изображения.
9. ruGPT
Сервис генерации видео «под ключ», который превращает текстовое описание или фотографию в готовый MP4-ролик с озвучкой, визуальным рядом и титрами без необходимости использовать какой-либо редактор. Аудитория платформы превышает 7 миллионов пользователей, что говорит о ее зрелости и стабильности. Сервис работает без VPN, поддерживает вертикальный формат для TikTok, Reels и YouTube Shorts. Видео из фото создается путем загрузки изображения и текстового описания — нейросеть самостоятельно достраивает динамику и звук. Максимальная длина ролика составляет 8 секунд, время генерации — несколько секунд.
- Тип поддерживаемых файлов: jpeg; png; mp4.
- Функции: генерация видео из текста и фото; автоматическая озвучка естественным голосом; вертикальный формат для соцсетей; выбор длительности и модели генерации; пакетная генерация по одному сценарию.
Плюсы:
- очень быстрая генерация — несколько секунд;
- реалистичная озвучка без роботизированного эффекта;
- простой интерфейс без порога входа;
- поддержка форматов для всех популярных соцсетей.
Минусы:
- максимальная длина ролика — 8 секунд;
- нет бесплатного режима; отсутствует встроенный редактор для доработки результата.
10. Chad AI
Chad AI предоставляет доступ к Veo 3.1 от Google — одной из самых мощных на сегодняшний день видеомоделей — с оплатой российской картой и без VPN. Сервис генерирует кинематографические ролики с синхронизированным звуком: диалогами, музыкой и эффектами, где движения губ персонажей точно совпадают с речью. Время генерации кадров составляет от 3 до 9 минут, зато результат отличается профессиональным постпродакшен-качеством. Модель глубоко понимает текстовые описания, включая операторские термины и визуальные стили. Поддерживает загрузку референсных изображений и видеофрагментов для управления направлением генерации.
- Тип поддерживаемых файлов: jpeg; png; mp4.
- Функции: генерация видео; синхронизация речи с движением губ; встроенная генерация звука — диалоги, музыка, эффекты; работа с референсными изображениями и видео; выбор соотношения сторон и длительности.
Плюсы:
- кинематографическое качество видео уровня профессиональной постпродакции;
- точная синхронизация губ и звука;
- глубокое понимание сложных текстовых промптов.
Минусы:
- долгое время генерации — до 9 минут;
- высокая стоимость на продвинутых тарифах;
- не подходит для быстрого прототипирования из-за времени ожидания.
11. AISearch
ИИ-ассистент с акцентом на работу с текстом и браузерное расширение для Chrome, позволяющее использовать нейросеть прямо на любом сайте без переключения вкладок. AISearch Video — инструмент внутри платформы AISearch, специализирующийся на оживлении статичных фотографий с помощью нейросети: сервис анализирует исходное изображение и воспроизводит естественные движения — моргание, улыбку, эффект наклона головы — создавая анимированный ролик длиной до 22 секунд.
- Тип поддерживаемых файлов: jpeg; png; mp4.
- Функции: оживление портретных и пейзажных фотографий; анимация лица — движения глаз, улыбка, моргание; добавление собственной аудиодорожки; наложение спецэффектов; экспорт видео в высоком качестве; интеграция с общей экосистемой AISearch.
Плюсы:
- максимальная длина ролика до 22 секунд — больше, чем у большинства аналогов;
- быстрая обработка за несколько секунд;
- поддержка собственного звука и спецэффектов;
- доступен в рамках единого аккаунта AISearch без дополнительной регистрации.
Минусы:
- заточен преимущественно под портретные фото;
- ограниченный контроль над параметрами анимации вручную;
- бесплатный лимит на платформе быстро исчерпывается.
Пошаговый план: создаю говорящее видео за пять минут
Подробнее разберу процесс на примере D-ID — одного из наиболее доступных сервисов с понятным интерфейсом. Принцип у большинства платформ схожий, поэтому инструкция применима с небольшими корректировками к любому другому инструменту. Именно так выглядит ответ на вопрос, как заставить фото говорить с помощью нейросети, в формате конкретного пошагового плана.
Шаг 1. Регистрация и выбор тарифа
Захожу на сайт d-id.com, создаю аккаунт через email или Google. На пробном тарифе доступно несколько минут видео — этого вполне хватает, чтобы оценить качество перед покупкой подписки. Рекомендую сразу пройти весь цикл на коротком тестовом ролике длиной 10–15 секунд: так быстрее понятно, устраивает ли качество именно на вашем материале.

Шаг 2. Загрузка исходного изображения
Нажимаю «Create Video» → «Add Presenter» → «Upload». Исходное изображение должно быть четким: лицо занимает большую часть кадра, освещение равномерное, фон нейтральный. Оптимальное разрешение видео определяется в том числе исходным разрешением снимка — загружаю минимум 512×512 пикселей, лучше 1024×1024.
Шаг 3. Добавление голоса
Здесь два варианта:
- Ввожу текст и выбираю голос из встроенной библиотеки доступных языков — сервис синтезирует речь автоматически с нужным эмоциональным окрасом.
- Загружаю готовый аудиофайл в формате MP3 или WAV с собственной голосовой записью.
Шаг 4. Настройка параметров
Выставляю разрешение видео (рекомендую минимум 720p) и при необходимости регулирую параметры голоса. Параметр частоты кадров (FPS) в большинстве сервисов фиксирован на 25 кадров в секунду — это стандарт для веб-публикаций, обеспечивающий достаточную плавность.
Шаг 5. Генерация и проверка качества
Нажимаю «Generate». Рендеринг в облаке занимает от 30 секунд до нескольких минут в зависимости от длины аудио. После завершения обязательно просматриваю ролик полностью и проверяю: нет ли артефактов изображения вокруг рта и подбородка, насколько естественные жесты и моргание вписываются в общую картину, не съезжает ли синхронизация губ к концу видео.
Шаг 6. Экспорт и постобработка звука
Скачиваю готовый MP4-файл. Если нужно добавить фоновую музыку или звуковые эффекты, открываю файл в любом видеоредакторе и провожу микширование звука уже там — не стоит совмещать его с этапом генерации, чтобы не ухудшить точность синхронизации губ.
Весь цикл — от загрузки снимка до скачивания готового ролика — укладывается в пять минут при наличии подготовленного исходного изображения и аудиодорожки.
Как использовать говорящее фото в соцсетях
Для Reels, TikTok и YouTube Shorts стандарт один — 9:16, разрешение от 1080×1920 px. Горизонтальные говорящие фото (16:9) подходят для YouTube и LinkedIn, квадрат 1:1 — для постов в Instagram и ВКонтакте. Если исходное фото горизонтальное, не просто кадрируйте его, а добавьте размытый фон по бокам — это делается в CapCut или Adobe Premiere. Лицо держите в верхней трети кадра, иначе субтитры перекроют его.
Субтитры добавлять обязательно: до 85% пользователей смотрят видео без звука, и они напрямую влияют на досмотр. Автосубтитры в CapCut или Captions App накладываются за минуту — крупный контрастный шрифт по центру нижней части экрана.
Чтобы не попасть под ИИ-фильтры платформ, добавьте живое вступление или закадровый голос реального человека, наложите реальную фоновую музыку или амбиентный звук — это «разбавляет» ИИ-сигнатуру. Лучше монтировать говорящее фото как часть ролика, а не весь ролик целиком. Синтезированному голосу помогает легкий эквалайзер и комнатный реверб — звук становится менее «стерильным». И там, где платформа требует маркировки AI-generated (YouTube, Instagram), честно ставьте метку: это снижает риск теневого бана за скрытое использование ИИ.
Исходник решает все: технические требования к фотографии
По моему опыту, качество финального ролика примерно на 60–70% определяется тем, насколько грамотно подобрано исходное изображение. Один и тот же сервис выдает принципиально разные результаты в зависимости от качества фото: на хорошем снимке анимация портрета выглядит живо и органично, на неудачном — алгоритм начинает «плавать», появляются артефакты изображения и смазанная артикуляция.
Что нужно учесть при подборе снимка:
- Лицо занимает большую часть кадра и смотрит прямо в камеру — допустимый поворот в сторону не превышает 15–20 градусов.
- Свет падает равномерно, без глубоких теней — особенно в нижней части лица, где алгоритм считывает движение рта.
- Фон простой и однородный — это помогает нейросети точнее обработать контуры лица и избежать визуальных искажений на готовом видео.
- Разрешение снимка — от 512×512 пикселей, оптимально 1024×1024 и выше.
- Рот закрыт или едва приоткрыт — второй вариант с видимыми зубами зачастую дает более правдоподобный результат при анимации речи.
- Глаза открыты — без этого модель не сможет корректно воспроизвести естественное движение век.
Чего лучше избегать:
- Снимков в профиль или с сильным поворотом головы — нейросеть не видит половину лица и начинает достраивать недостающие части, что приводит к заметным искажениям.
- Фотографий с тяжелыми фильтрами, замыливанием кожи или агрессивной обработкой — чрезмерно сглаженная текстура мешает модели точно считать геометрию лица.
- Изображений, где часть лица закрыта: темные очки, медицинская маска или челка, падающая на глаза, — все это лишает алгоритм нужных опорных точек.
- Групповых фотографий: большинство платформ работает только с одним лицом в кадре, остальные персонажи либо игнорируются, либо провоцируют ошибки.
- Размытых или пикселизированных снимков — низкое качество исходника не исправляется в процессе обработки, а визуальные дефекты на финальном видео становятся только заметнее.
Дополнительный совет: темный или смазанный снимок стоит предварительно обработать в одном из бесплатных онлайн-инструментов — Remini, Adobe Express или аналогичном сервисе повышения четкости. Это простой шаг, который заметно улучшает итоговый результат: нейросеть получает более качественный материал для анализа, а финальное видео выходит чище — без размытых контуров и лишних визуальных погрешностей.
Голос и лицо в унисон: как добиться идеальной синхронизации
Липсинк — самый технически сложный элемент в технологии говорящих фото. Именно здесь кроются основные проблемы плохих результатов: губы чуть запаздывают, артикуляция смазывается на сложных звуках, или движения выглядят механически. Чтобы этого избежать, важно не только правильно подобрать фото, но и грамотно подготовить аудиодорожку.
Требования к аудиофайлу:
- Формат — WAV (44,1 кГц, 16 бит) или MP3 (320 kbps). WAV предпочтительнее: нет сжатия с потерями, фонемный анализ точнее.
- Длительность — большинство бесплатных тарифов ограничивают ролик 30–60 секундами; на платных планах лимит значительно выше.
- Качество записи — без фонового шума, реверберации и эха. Чем чище запись, тем точнее алгоритм определяет границы фонем и строит синхронизацию губ.
- Темп речи — умеренный. Слишком быстрая речь затрудняет фонемный анализ; слишком медленная делает мимику неестественной и затянутой.
При самостоятельной записи голоса достаточно петличного микрофона или тихого помещения с мягкой мебелью — она поглощает отражения и убирает эхо. Готовую запись стоит обработать в Audacity: подавить фоновый шум через Noise Reduction и нормализовать громкость до –3 dB. Если используете встроенный голосовой движок, обратите внимание на тональность: большинство платформ предлагают нейтральную, дружелюбную, официальную и энергичную подачу — для рекламы подойдет динамичный голос, для обучения — спокойный и разборчивый. HeyGen и D-ID дополнительно поддерживают клонирование голоса: загрузите несколько минут собственной речи, и модель создаст персонализированный голосовой профиль. Точность липсинка при этом обеспечивается фонемным анализом: алгоритм разбивает аудиодорожку на минимальные звуковые единицы и сопоставляет каждую с положением рта, щек и языка, параллельно просчитывая поворот головы, моргание и смещение бровей — именно эта совокупность деталей делает образ живым.
Лицом к лицу: сравниваю популярные платформы
Для тех, кто хочет получить говорящее фото ИИ бесплатн, я свожу ключевые характеристики одиннадцати популярных платформ в одну таблицу. Оценки основаны на тестах и пользовательских отзывах 2025–2026 годов.
| Сервис | Бесплатный план | Качество липсинка | TTS | Клонирование голоса | Цена |
|---|---|---|---|---|---|
| MashaGPT | ✅ 12 сообщ./3 ч | ✅ Через Kling 2.0 | ✅ ElevenLabs v3 | ❌ Нет | от 990 ₽/мес |
| Study AI | ✖️ Ограничен | ✅ Через Kling AI | ✅ ElevenLabs | ❌ Нет | от 199 ₽/мес |
| Kling | ✖️ Ограничен | ✅ Высокое (нативный Kling) | ❌ Нет | ❌ Нет | от 199 ₽/мес |
| Apihost | ❌ Нет | ❌ Нет | ✅ от 0,6 ₽/1000 симв. | ✅ Fast-clone бесплатно, Pro-clone 1 000 ₽/голос | от 490 ₽ + 30 ₽/сек видео |
| SmartBuddy | ✅ Есть | ❌ Нет | ✅ Есть | ❌ Нет | оплата за использованную функцию (pay‑as‑you‑go) |
| GoGPT | ✅ 10 запросов/день | ✅ Через Kling / HeyGen | ❌ Нет | ❌ Нет | от 699 ₽/мес |
| Flyvi | ✅ 5 дней пробный | ❌ Нет | ✅ В промпте к видео | ❌ Нет | от 599 ₽/мес |
| ruGPT | ❌ Нет | ❌ Нет | ✅ Авто-озвучка в видео | ❌ Нет | от 165 ₽ в месяц |
| GPTunneL | ✖️ Ограничен | ❌ Нет | ❌ Нет | ❌ Нет | от 54 ₽ за видео |
| Chad AI | ✖️ Ограничен | ✅ Высокое (Veo 3.1) | ✅ Авто-звук в видео | ❌ Нет | от 290 ₽/мес |
| AISearch | ✅ 3 000 симв./день | ❌ Нет | ❌ Нет | ❌ Нет | от 99 ₽/мес |
Часто задаваемые вопросы
Можно ли создать говорящее фото бесплатно?
Да. Из рассмотренных платформ бесплатный пробный доступ предлагают D-ID (несколько коротких роликов), HeyGen (1 минута видео), DupDub (10 кредитов без привязки карты) и Plotaverse (базовый функционал без ограничений по времени). Этого вполне достаточно, чтобы оценить, как конкретная нейросеть с функцией говорящего фото справляется именно с вашим материалом — до покупки подписки.
Это законно — анимировать фотографию другого человека?
Использование чужих фотографий без согласия — юридически и этически серьезная проблема, особенно на фоне активно развивающегося законодательства о дипфейках в России, ЕС и США. Большинство платформ в пользовательском соглашении прямо требуют подтверждения прав на загружаемое изображение. Безопасный путь — использовать собственные снимки, фотографии с явного письменного согласия изображенного человека или изображения из стоков с соответствующей лицензией. Нарушение этого правила может повлечь блокировку аккаунта и юридические последствия.
Почему губы двигаются неестественно?
Чаще всего проблема кроется в качестве исходных материалов: размытый или сильно обработанный снимок не дает алгоритму точно считать геометрию лица, а шум в аудиозаписи мешает корректно разобрать произносимые звуки — в результате движение рта и речь расходятся. Вторая частая причина — слишком боковой ракурс на фото: модель видит лицо частично и начинает достраивать недостающее, что неизбежно приводит к визуальным искажениям в готовом видео. Решение в обоих случаях одно: подготовьте более качественный снимок, уберите шум из аудиодорожки и запустите генерацию заново.
Что делать, если нейросеть не справляется с русскими звуками?
Не все платформы одинаково хорошо справляются с русской речью — это заметно именно на качестве движения губ. Если результат на русском явно уступает тому, что сервис показывает на английском демо, попробуйте переключиться на встроенный голосовой движок платформы вместо загрузки собственной записи: внутренние речевые модели, как правило, оптимизированы под конкретные языки и дают более точное совпадение звука с положением рта. Если проблема сохраняется, стоит рассмотреть русскоязычные платформы — в частности, Study AI: они изначально разрабатывались с учетом особенностей кириллической фонетики и на практике показывают более аккуратный результат на русском, чем большинство зарубежных аналогов.
Можно ли анимировать нарисованного персонажа или аватар?
Да — большинство современных платформ работают не только с реальными снимками, но и с рисованными персонажами, аниме-стилистикой и цифровыми образами. Ключевое условие одно: лицо на изображении должно быть четко читаемым, с узнаваемыми пропорциями. Чем ближе внешность персонажа к человеческой, тем увереннее алгоритм считывает нужные опорные точки и тем органичнее выглядит итоговая анимация. Сильно стилизованные образы — с непропорционально крупными глазами, вытянутыми чертами или намеренно искаженной геометрией лица — обрабатываются заметно хуже: рассчитывайте на более грубый результат и характерные визуальные погрешности в зоне рта и глаз.
Технология говорящих фото прошла путь от спецэффектов с многомиллионным бюджетом до инструмента в браузере обычного пользователя. Нейросеть для создания говорящих фото — это не эксперимент, а полноценный рабочий инструмент для маркетологов, педагогов, блогеров и всех, кому нужен живой человеческий образ без съемочной группы. Чтобы получить хороший результат, достаточно трех вещей: качественный снимок анфас, чистая аудиозапись и правильно выбранная платформа. Начните с бесплатных тарифов, протестируйте два-три сервиса на собственном материале — и ИИ говорящее фото быстро перестанет казаться чем-то сложным или недоступным.
Если у вас уже есть опыт работы с подобными сервисами — поделитесь им в комментариях: какую платформу использовали, с какими сложностями столкнулись и какой результат получили. Обсудим нюансы и разберем конкретные случаи вместе.

Комментарии к статье
С появлением ии стало очень сложно отличить где вымысел, а где реальность
1 ответ
Это точно.. и сейчас стало еще сложнее различать, чем раньше... Недавно мне на глаза попались старые сгенерированные картинки 2023 г и мне они показались смешными какими-то...х)