Как работает искусственный интеллект: простое объяснение без формул и технозауми

Вопрос о том, как работает искусственный интеллект, волнует миллионы людей, когда они сталкиваются с нейросетями, чат-ботами или системами рекомендаций. В этой статье я разберу, как устроены современные модели ИИ, почему нейросети могут распознавать изображения, писать тексты, и какие математические принципы лежат в основе этих технологий.
Когда я впервые начал разбираться, как работает искусственный интеллект, меня удивило, что ключевой скачок в развитии ИИ произошел не из-за появления новых идей, а благодаря росту вычислительных мощностей, огромным объемам данных и развитию алгоритмов обучения. Современные модели могут анализировать миллиарды параметров, а их обучение происходит на гигантских наборах данных, которые формируют так называемую обучающую выборку.
В этой статье я последовательно объясню, как работают нейросети простыми словами. Разберу биологическое вдохновение нейросетей, покажу путь сигнала через модель, расскажу о математике под капотом и объясню, как происходит обучение.
Биологическое вдохновение: устройство нейросети
Нейросеть — это математическая модель, которая имитирует принцип работы нейронов в человеческом мозге. Идея такого подхода появилась еще в середине 20 века, когда ученые попытались описать процессы мышления с помощью математики. Они заметили, что мозг человека состоит из огромного количества нейронов, соединенных между собой. Каждый нейрон получает сигналы от других клеток, обрабатывает их и передает дальше.

Если говорить проще, устройство нейросети можно представить как систему взаимосвязанных вычислительных элементов. Каждый из них выполняет относительно простую операцию, но вместе они способны решать сложные задачи:
- распознавать изображения;
- переводить тексты;
- даже прогнозировать события.
В основе такой системы лежит схема соединения всех элементов, определяющая, как происходит обработка информации. Структура нейросети состоит из трех частей:
- Входной слой.
- Скрытые слои.
- Выходной слой.
Каждый из этих уровней выполняет функцию в процессе анализа данных.
Входной слой принимает входные данные модели. Это может быть информация, представленная в числовом виде.
- Например, если система анализирует изображение, входными данными становятся значения пикселей.
- Если нейросеть работает с текстом, слова сначала преобразуются в числовые векторы.
- При анализе финансовых данных входными параметрами могут быть показатели рынка, цены активов или экономические индикаторы.
После получения информации данные передаются дальше по сети. При этом каждый элемент входного слоя отправляет сигнал нескольким нейронам следующего уровня. Уже на этом этапе начинается обработка информации, поскольку данные подготавливаются для дальнейших вычислений.

Основная работа происходит в скрытых слоях. Здесь выполняется большая часть математических операций, через которые модель находит закономерности в данных. Каждый скрытый слой представляет собой вычислительный алгоритм, в котором происходит преобразование входной информации.
Нейроны внутри слоя:
- получают значения;
- умножают их на специальные коэффициенты;
- и передают результат дальше.
Чем больше скрытых слоев содержит линейная модель, тем сложнее задачи она может решать. Когда таких уровней становится много, говорят о глубокой архитектуре. Глубокая архитектура разрешает системе постепенно извлекать сложные признаки из данных.
- Например, при анализе изображения первые слои могут распознавать простые элементы — линии и углы.
- Следующие слои начинают объединять их в формы и контуры.
- А более глубокие уровни уже способны распознавать объекты: лица людей, автомобили или животных.
Последний этап обработки происходит в выходном слое. Его задача — преобразовать результаты вычислений в понятный итоговый ответ. Выходной слой формирует решение модели на основе всей информации, прошедшей через сеть. Например, система может определить, что на изображении кошка с вероятностью 95%.
Важно понимать, что структура нейросети может сильно отличаться в зависимости от задачи. В некоторых моделях используется всего несколько слоев, в других — десятки или даже сотни. Современные системы искусственного интеллекта могут включать миллиарды параметров и огромные сети взаимосвязанных нейронов.
Несмотря на сложность таких моделей, базовое устройство ИИ остается относительно простым:
- данные поступают на вход;
- проходят через серию вычислительных слоев, где выполняются математические преобразования;
- и на выходе формируется результат.
Благодаря такой структуре нейросети способны постепенно обучаться, улучшать точность предсказаний и находить закономерности в огромных объемах информации.
Как работает искусственный интеллект простыми словами: от нейрона до результата
Несмотря на сложность современных систем искусственного интеллекта, базовый принцип их работы довольно логичен. Процесс можно представить как простую математическую формулу, которая объединяет несколько входных параметров.
После суммирования применяется нелинейное преобразование — специальная математическая операция, которая изменяет полученное значение. На этом этапе нейрон принимает решение о том, насколько важен полученный сигнал и нужно ли передавать его дальше.
Если бы нейросеть выполняла только сложение и умножение, она фактически представляла бы собой обычную линейную модель. Такие модели могут находить только простые зависимости между данными. Но реальные задачи — например, распознавание изображений или понимание текста — гораздо сложнее. Поэтому нейросетям необходимы дополнительные математические механизмы, позволяющие анализировать сложные структуры данных.
После обработки результат передается следующему нейрону или следующему слою сети. Этот процесс повторяется множество раз. Сигнал проходит через десятки или даже сотни вычислительных слоев, постепенно трансформируясь и уточняясь. На каждом этапе нейросеть извлекает новые признаки из данных и формирует все более точное представление о задаче.
Веса и смещения. Что это такое и почему они важны
Если говорить о том, как работают нейросети простыми словами, то непозволительно обойти стороной обучающие параметры — веса и смещения. Они определяют, как модель будет реагировать на разные входные сигналы.
Вес показывает, насколько важен конкретный входной сигнал для нейрона. Если значение веса большое, нейрон сильнее реагирует на соответствующий параметр. Если вес близок к нулю, влияние сигнала практически игнорируется. Таким образом сеть постепенно учится выделять наиболее значимые признаки в данных.
Например, при распознавании изображений одни нейроны могут сильнее реагировать на линии, другие — на формы или цвета. Весовые коэффициенты позволяют модели определить, какие элементы изображения имеют наибольшее значение для итогового результата.
Смещение — это дополнительный параметр, который добавляется к сумме входных сигналов. Его задача — сместить итоговое значение нейрона и сделать модель более гибкой. Благодаря смещениям нейросеть может корректнее адаптироваться к различным данным и точнее описывать сложные зависимости.

В процессе обучения происходит оптимизация модели. Алгоритм постепенно изменяет веса и смещения, стремясь уменьшить ошибку ответа. Этот процесс может включать миллионы или даже миллиарды изменений параметров. Постепенно модель начинает лучше понимать структуру данных и повышает точность ответа.
Таким образом веса и смещения — ключевые элементы, определяющие поведение нейросети. Они позволяют системе адаптироваться к данным и улучшать результаты работы.
Функции активации. Зачем нейрону «принимать решение»
После выполнения математических операций нейрон применяет активационную функцию. Это специальная математическая операция, которая определяет, должен ли сигнал передаваться дальше по сети.
Можно сказать, что активационная функция играет роль своеобразного фильтра. Она помогает нейрону «решить», насколько важен полученный сигнал и стоит ли его учитывать при дальнейших вычислениях. Благодаря этому нейросеть может находить сложные закономерности, которые невозможно описать с помощью простых линейных зависимостей.
В современных моделях используются разные типы функций активации. Наиболее распространенные из них:
- ReLU — одна из самых популярных функций. Она пропускает только положительные значения и обнуляет отрицательные. Благодаря своей простоте она ускоряет обучение моделей.
- Sigmoid — функция, которая преобразует любое число в значение от 0 до 1. Она часто используется в задачах, где требуется определить вероятность события.
- Tanh — функция, похожая на sigmoid, но возвращающая значения в диапазоне от -1 до 1. Она позволяет учитывать как положительные, так и отрицательные сигналы.
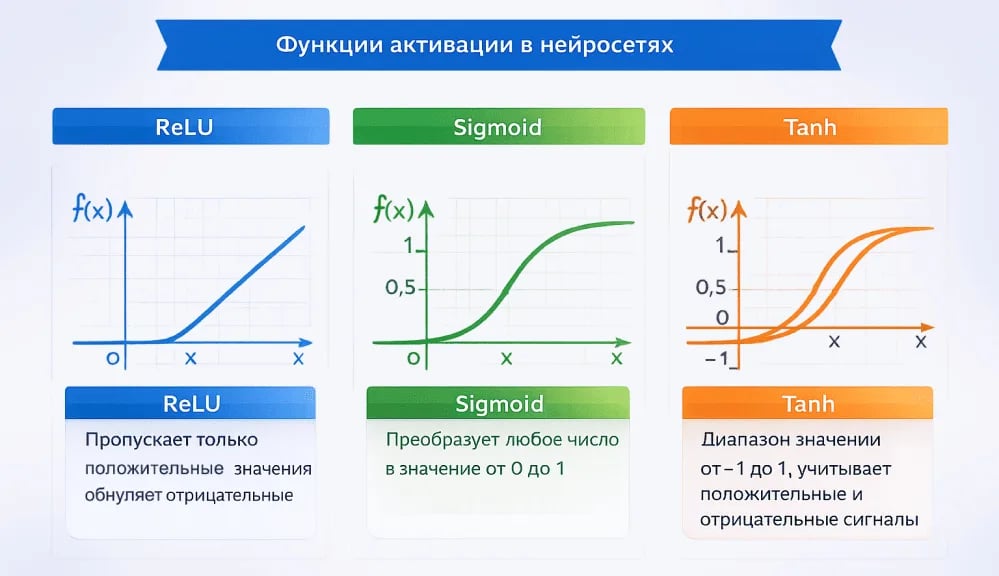
Каждая из этих функций по-разному влияет на обработку информации нейросетью и может использоваться в разных типах задач.
Обратное распространение ошибки. Как сеть понимает, что она ошиблась
Один из самых важных механизмов обучения нейросетей — это обратное распространение ошибки. Благодаря этому процессу модель может постепенно улучшать свои ответы.
- Когда нейросеть делает предсказание, результат сравнивается с правильным ответом.
- Разница между ними называется функцией ошибки.
- Она показывает, насколько сильно модель отклонилась от правильного результата.
После вычисления ошибки начинается процесс обучения. Специальный алгоритм оптимизации анализирует полученное значение и определяет, какие параметры модели необходимо изменить.
Затем ошибка распространяется обратно по всей сети — от выходного слоя к входному. На каждом этапе вычисляется вклад каждого нейрона в итоговую ошибку. Это позволяет понять, какие веса нужно скорректировать.
Во время каждой итерации обучения параметры модели немного изменяются. Постепенно вероятность ошибки уменьшается, а точность ответа растет.
Такой процесс повторяется огромное количество раз. Современные модели могут проходить миллионы итераций обучения, прежде чем достигнут нужного уровня точности.
Благодаря обратному распространению ошибки нейросети способны обучаться на больших объемах данных, адаптироваться к новым задачам и постепенно улучшать качество своих прогнозов.
Математика под капотом: как работает AI на самом деле
Если заглянуть глубже и попытаться понять, как работает современный искусственный интеллект, становится очевидно: в основе всех процессов лежит математика. Любая обработка информации нейросетью фактически представляет собой большое количество математических вычислений, которые выполняются над числами. Чем сложнее модель и чем больше в ней параметров, тем больше таких операций происходит внутри системы.
Чтобы лучше понять этот процесс, можно представить входные данные как набор чисел. Например, изображение состоит из пикселей, и каждый пиксель можно описать числовым значением яркости или цвета. Текст тоже можно преобразовать в числа — для этого используются специальные методы кодирования слов. В результате любая информация, поступающая в модель, превращается в числовой вектор.
Вектор — это упорядоченный набор чисел. Он может описывать различные характеристики объекта:
- свойства изображения;
- параметры звука;
- смысловое представление текста.
Такие векторы служат отправной точкой для дальнейших вычислений.
Следующий важный элемент — матрицы. В контексте нейросетей матрицы чаще всего используются для хранения весовых коэффициентов модели. Каждая матрица описывает связи между нейронами разных слоев. Когда сигнал проходит через слой, где выполняется умножение вектора входных данных на матрицу весов.
Эта операция называется матричным умножением. После нее результат проходит дополнительные преобразования. Таким образом выполняется один шаг обработки данных внутри сети.
Подобные операции происходят на каждом уровне модели. Каждый вычислительный слой выполняет большое количество матричных операций, постепенно преобразуя данные и извлекая из них важные признаки. Если в сети десятки или сотни слоев, то общее количество вычислений становится огромным.
В результате последовательность математических преобразований позволяет модели перейти от набора чисел к осмысленному результату.
Отдельно стоит упомянуть алгоритмы оптимизации, которые используются во время обучения моделей. Они также основаны на математике. Один из ключевых методов — градиентный спуск. Этот алгоритм помогает определить, в каком направлении нужно изменить обучающие параметры, чтобы уменьшить функцию ошибки.
Во время обучения модель выполняет огромное количество вычислений. Каждая итерация обучения включает 3 этапа: прямой проход данных через сеть, вычисление ошибки и корректировку параметров. В современных системах таких итераций может быть миллион.
Поэтому обучение нейросетей требует колоссальных вычислительных ресурсов. Обычные центральные процессоры не всегда способны справиться с таким объемом операций быстро. Поэтому для обучения искусственного интеллекта активно используются графические процессоры — GPU.
GPU изначально создавались для обработки графики, но они подходят и для работы с нейросетями. Их архитектура позволяет выполнять тысячи операций одновременно. Это особенно важно для матричных вычислений, которые лежат в основе работы нейросетей.
Благодаря параллельным вычислениям GPU могут ускорять обучение моделей. Если на обычном процессоре обучение крупной нейросети могло бы занять годы, использование графических ускорителей позволяет сократить это время до дней или даже часов.
Таким образом, несмотря на внешнюю сложность искусственного интеллекта, его работа сводится к огромному количеству математических операций. Векторы, матрицы и алгоритмы оптимизации образуют фундамент, на котором строится вся архитектура современных нейросетей. Эта математическая основа делает возможным создание моделей, способных анализировать объемы данных и находить в них закономерности.
Обучение: как работает ИИ простыми словами
Главная задача обучения нейросети — подобрать такие обучающие параметры, которые позволят модели точно выполнять поставленную задачу. Это может быть:
- распознавание объектов на изображении;
- перевод текста;
- определение тональности сообщения;
- прогнозирование числовых значений.
Чтобы добиться высокой точности, модель должна постепенно научиться выявлять закономерности в данных и корректно применять их при анализе новой информации.
Для этого используется выборка — специальный набор данных, на котором система тренируется. Такая выборка может включать тысячи, миллионы или даже миллиарды примеров. Каждый пример содержит входные данные и, в большинстве случаев, правильный ответ, с которым можно сравнить результат работы алгоритма.
Например, если нейросеть обучается распознавать изображения животных, выборка будет содержать большое количество фотографий, каждая из которых подписана соответствующей категорией:
- кошка;
- собака;
- птица и так далее.

Анализируя такие данные, система постепенно учится различать визуальные признаки разных объектов. Процесс обучения обычно проходит в несколько последовательных этапов:
- Модель получает данные.
- Делает прогноз.
- Вычисляется функция ошибки.
- Алгоритм изменяет параметры.
Сначала система получает входные данные из обучающей выборки. Эти данные проходят через все вычислительные слои сети, где происходит их преобразование. На основе текущих параметров обучения модель формирует прогноз.
После этого вычисляется ошибочная функция. Она показывает, насколько результат модели отличается от правильного ответа. Чем больше ошибка, тем сильнее модель отклоняется от нужного результата.
Следующий этап — работа алгоритма оптимизации. Его задача заключается в том, чтобы изменить обучающие параметры таким образом, чтобы уменьшить значение функции ошибки. Алгоритм анализирует вклад каждого параметра в итоговый результат и корректирует веса сети.
Однако важно понимать, что обучение нейросетей может происходить по-разному. В машинном обучении выделяют три основных подхода.
- Обучение с учителем — самый распространенный тип обучения нейросетей. В этом случае каждый элемент обучающей выборки содержит не только входные данные, но и правильный ответ. Модель получает данные, делает прогноз, а затем сравнивает его с правильным ответом. Если результат отличается, алгоритм корректирует обучающие параметры. Такой подход широко используется в задачах распознавания изображений, обработки текста, медицинской диагностики, финансового прогнозирования. Главное преимущество метода — высокая точность предсказаний при наличии качественных данных.
- Обучение без учителя работает иначе. В этом случае модель получает только входные данные, но правильные ответы заранее неизвестны. Задача алгоритма — самостоятельно найти структуру и закономерности в данных. Например, система может группировать похожие объекты, находить скрытые связи, выявлять аномалии. Такой подход часто используется в задачах кластеризации. Например, интернет-магазин может анализировать поведение пользователей и автоматически выделять группы клиентов с похожими интересами. Хотя обучение без учителя менее контролируемое, оно помогает исследовать большие массивы информации и находить неожиданные закономерности.
- Еще один важный подход — обучение с подкреплением. В этом случае модель обучается через взаимодействие со средой. Алгоритм выполняет определенные действия и получает обратную связь в виде награды или штрафа. Постепенно система учится выбирать те действия, которые приводят к наилучшему результату. Такой метод используется в задачах управления роботами, разработке игровых ИИ, оптимизации логистики, автономном вождении.


Классический пример — обучение программ, которые играют в шахматы. Система делает ход, оценивает результат и постепенно улучшает свою стратегию.
Независимо от типа обучения, ключевую роль играют датасеты. Данные определяют, какие закономерности сможет изучить модель.
Если обучающая выборка маленькая или содержит ошибки, качество работы системы резко снижается. Кроме того, данные должны быть разнообразными, чтобы модель могла корректно работать с новыми ситуациями.
После завершения обучения проводится тестирование на отдельном наборе данных. Это помогает проверить, насколько хорошо система обобщает знания и применяет их к новым примерам.
Иногда возникает проблема переобучение модели. В этом случае система слишком точно запоминает обучающие данные и плохо работает на новой информации. Чтобы избежать этого, разработчики используют различные методы оптимизации модели, включая регуляризацию весов и специальные техники контроля обучения.
В результате правильно организованный процесс обучения позволяет нейросети постепенно улучшать качество прогнозов и эффективно работать с большими объемами информации.
Как устроен искусственный интеллект: типы архитектур
Когда я начал глубже изучать современные нейросети, стало понятно, что универсальной модели не существует. Разные задачи требуют разных подходов. Поэтому инженеры создают различные архитектуры нейронных сетей, каждая из которых лучше подходит для конкретного типа данных.
Архитектура ИИ определяет, как соединены слои, как передается информация между ними и какие математические операции выполняются внутри модели. При этом базовое устройство нейросети остается похожим: входные данные проходят через несколько вычислительных слоев, где происходит обработка информации, и на выходе формируется результат.
Современные системы искусственного интеллекта часто используют глубокую архитектуру — модели, содержащие десятки или даже сотни слоев. Благодаря такой структуре искусственной нейросети она может извлекать сложные признаки из данных и решать задачи, которые раньше считались невозможными для машин. Рассмотрим три наиболее распространенных типа архитектур.
1. Трансформеры
Сегодня большинство современных языковых моделей построены на архитектуре трансформеров. Эта технология лежит в основе многих известных систем генерации текста. Главная особенность трансформеров заключается в механизме внимания. Он позволяет модели анализировать взаимосвязи между элементами данных — например, словами в предложении. Когда система получает текст, входные данные преобразуются в числовые представления. Затем они проходят через несколько вычислительных слоев, где выполняются сложные матричные операции. Каждый слой анализирует контекст и определяет, какие элементы текста важнее остальных. Благодаря этому модель понимает смысл фразы. Такая архитектура нейронной сети особенно хорошо работает с текстами, программным кодом и большими документами.
2. Сверточные нейронные сети
Для работы с изображениями чаще используются сверточные нейронные сети. Их архитектура вдохновлена работой зрительной системы человека. Когда человек смотрит на изображение, мозг сначала распознает простые элементы — линии и формы — а затем объединяет их в более сложные объекты. Сверточные сети работают похожим образом. Они применяют специальные фильтры, которые анализируют небольшие участки изображения. На каждом этапе слой выделяет новые признаки: края объектов, текстуры, формы, сложные структуры. Постепенно сеть формирует более сложное представление картинки. В результате система может определить, что изображено на фотографии. Такая архитектура широко применяется в системах распознавания лиц, медицинской диагностике, беспилотных автомобилях, анализе спутниковых снимков.
3. Рекуррентные нейронные сети
Для обработки последовательностей данных раньше активно использовались рекуррентные нейронные сети. Их особенность в том, что они могут учитывать предыдущие элементы последовательности. Это особенно важно при работе с текстом, звуком и временными рядами. Например, при анализе предложения модель должна учитывать предыдущие слова, чтобы правильно интерпретировать смысл. Рекуррентные сети передают информацию из предыдущих шагов в следующие, что позволяет учитывать контекст. Однако со временем стало ясно, что такие модели плохо масштабируются на большие объемы данных. Поэтому сегодня их часто заменяют трансформеры. Тем не менее рекуррентные сети по-прежнему используются в некоторых задачах обработки сигналов и анализа временных данных.
Архитектура ИИ напрямую определяет возможности модели и область ее применения. Одни архитектуры лучше подходят для анализа изображений, другие — для обработки текста или временных последовательностей. Поэтому в современных системах искусственного интеллекта часто используются разные типы сетей или их комбинации. Понимание того, как устроена структура искусственной нейросети и какие архитектуры используются для различных задач, помогает лучше представить, как происходит обработка информации и почему одни модели эффективнее в определенных сценариях.
FAQ
Как работает искусственный интеллект — это сложная программа?
Отчасти да, но с одним отличием. Классическая программа выполняет заранее прописанные инструкции: если произошло событие A — выполнить действие B. Искусственный интеллект работает иначе: он не получает готовые правила. Вместо этого система сама ищет закономерности в данных, анализирует их и подбирает оптимальные параметры для решения конкретной задачи.
Во время обучения система многократно проходит через обучающую выборку, корректируя веса и смещения, применяя функции активации и алгоритмы оптимизации. С каждой итерацией точность предсказания повышается. В итоге программа адаптируется к данным и может решать задачи, которые невозможно описать обычным кодом.
Может ли нейросеть по-настоящему «думать»?
У нейросети нет сознания, они не умеют думать в человеческом смысле. У них нет намерений, эмоций или понимания контекста, как человек. Вместо этого они выполняют массив математических вычислений и находят статистические закономерности в данных.
Обработка информации строится на таких операциях, как матричные умножения, нелинейные преобразования и функции активации. Модель анализирует входные данные, преобразует их через слои сети и на выходе формирует результат. Поэтому корректнее говорить, что нейросеть прогнозирует исход на основе информации, которую получила при обучении, а не размышляет или принимает решения в человеческом понимании.
В чем главное отличие нейросети от классического кода?
Главное отличие — в подходе к решению задач. В традиционном программировании разработчик сам прописывает точные правила и последовательность действий: «если A — то B». Отклонение от прописанного сценария может привести к ошибке. Нейросеть получает входные данные и самостоятельно ищет закономерности через обучение. Разработчик задает только структуру искусственной нейросети, механизм оптимизации и базовые параметры обучения, а сама система учится на данных, постепенно улучшая точность предсказаний.
Почему нейросети иногда ошибаются (галлюцинации)?
Во-первых, модель может столкнуться с данными, которых не было в обучающей выборке. В таких случаях система делает прогноз, опираясь на аналогии, и результат может быть неверным.
Во-вторых, иногда возникает переобучение. Это происходит, когда нейросеть слишком хорошо запоминает обучающие данные, вместо того чтобы выявлять общие закономерности. В итоге она работает плохо на новых примерах.
Также ошибки могут быть связаны с ограничениями архитектуры нейронной сети: слишком маленькая или неглубокая сеть не способна анализировать сложные данные, а слишком сложная сеть без достаточного объема датасета переобучается.
Чтобы снизить вероятность ошибок, разработчики используют методы регуляризации, расширяют обучающую выборку, контролируют качество данных и проводят тщательное тестирование модели.
Сложно ли создать нейросеть с нуля?
Теоретически создать нейросеть может даже начинающий разработчик. Библиотеки вроде TensorFlow, PyTorch и Keras упрощают процесс: от создания слоев до обучения модели.
Однако создание крупной модели требует серьезных ресурсов. Необходим большой объем обучающих данных, мощное оборудование (CPU и GPU), опыт работы с архитектурами нейросетей и алгоритмами оптимизации. Важно правильно настраивать параметры обучения, контролировать функцию ошибки, проводить тестирование модели и предотвращать переобучение.
Вот мы и разобрались, как работает искусственный интеллект. Современные системы искусственного интеллекта могут казаться магическим: они пишут тексты, распознают изображения, создают музыку и помогают принимать решения. Но если разобрать технологию изнутри, становится ясно, что за этими возможностями стоит сложная комбинация математики, статистики и вычислительных мощностей. Архитектура ИИ, огромные датасеты и постоянная оптимизация позволяют алгоритмам находить закономерности в данных и постепенно повышать точность предсказаний.
А как вы думаете — сможет ли искусственный интеллект в будущем приблизиться к человеческому мышлению? Интересно узнать мнение в комментариях.

Комментарии к статье
Да, а ведь не зря говорят, что нужно учиться у природы. Она - самый лучший создатель.) И в случае с нейросетями - также, получается.. Есть такие мнения, что ИИ в дальнейшем настолько сильно разовьётся, что сможет стать "сверхразумом" и сможет управлять людьми. Но это что-то похоже больше на утопию, как по мне. Скорее, ии будет помогать в управлении процессами и пр., как сейчас точечно это бывает.) Хотя, как знать... Я на днях услышала по радио, что в Швеции запустили экспериментальный проект (кафе вроде), где компанией управляет ИИ, а подчиняется ему работники-люди. Сказали, что по-большей части ИИ-начальник справлялся со своими задачами, но не везде: где-то по его распоряжению закупали слишком большие партии товара, что не следовало делать...х) Это интересно, конечно...