Как я создаю песни с помощью нейросети: от текста до трека, который не стыдно показать

Раньше для записи собственного трека нужна была студия, звукорежиссер, живые музыканты и немалый бюджет, порой десятки тысяч рублей только за сессионную работу. Сегодня все это заменяет браузер и правильно составленный промпт. Я сам попробовал несколько популярных платформ и разобрался, как создать песню с помощью нейросети так, чтобы результат звучал по-настоящему, а не как черновой набросок из одного случайного дубля. Порог входа стал настолько низким, что с задачей справляется человек без нотной грамоты и без микрофона.
В статье я разберу лучшие ИИ для создания музыки: Suno, Udio, MusicLM от Google и AIVA. Объясню, на каком принципе работают эти инструменты, покажу пошаговую инструкцию записи трека с нуля, поделюсь советами по написанию промптов для текста песни и расскажу, как не выйти за рамки бесплатного плана. В конце вас ждут сравнительная таблица сервисов и ответы на самые частые вопросы.
Революция в звуке: как ИИ для создания музыки изменил индустрию
Генеративная музыка — это звук, созданный алгоритмом без прямого участия человека-музыканта. Модель анализирует паттерны из огромного массива обучающих данных и синтезирует новый аудиоматериал, который следует тем же закономерностям. Если упростить совсем, нейронка делает то, что раньше умел только опытный аранжировщик. Она слышит внутреннюю структуру трека и выстраивает новый по той же логике.
Принцип работы современных музыкальных моделей основан на трансформерной архитектуре — той же, что стоит за языковыми алгоритмами вроде GPT. Только вместо токенов-слов здесь токены-звуки. Нейросеть проходит обучение на миллионах часов аудио, чтобы предсказывать, какой фрагмент мелодии или ритмической фразы идет следующим. Именно поэтому результат звучит связно, а не как случайный набор нот.
Ключевое отличие последнего поколения инструментов в том, что они умеют работать одновременно с несколькими уровнями. Нейросеть анализирует тембр голоса, выбирает подходящий ритм под заданный жанр, подстраивает гармонию под настроение текста. Раньше каждая из этих задач требовала отдельного специалиста. Сейчас весь процесс умещается в одну форму ввода на сайте.
Прорыв произошел не случайно. В 2020–2021 годах компании начали обучать модели на огромных датасетах лицензированной музыки. Google выпустил MusicLM, Meta* открыла код MusicGen, а стартап Suno показал, что искусственный интеллект способен генерировать полноценные песни с лирикой и вокалом. Звук перестал быть исключительной прерогативой людей, получивших образование в консерватории.
Важно понимать, что ИИ для создания музыки не заменяет полностью живых исполнителей, скорее, он снимает технический барьер между идеей и ее воплощением. Если у вас есть мелодия в голове или несколько строчек текста, нейронка поможет превратить это в полноценный трек за считаные минуты. Дальше уже вопрос вкуса и дополнительной корректировки, можно оставить как есть или доработать в аудиоредакторе.
Еще один важный аспект — данные для обучения нейросети. Опенсорсные модели вроде MusicGen используют датасеты с открытыми лицензиями. Это влияет не только на юридическую чистоту, но и на качество. Чем разнообразнее и качественнее обучающий материал, тем богаче звуковая палитра результата.
За последние два года ИИ для создания песен прошел путь от генерации простых инструментальных петель до полноценных композиций с осмысленным текстом и человекоподобным вокалом. Suno в 2023 году показал, что модель способна выдавать треки, которые уже сложно отличить от работы живого исполнителя на демозаписи. Это изменило само представление о том, кто может быть автором музыки.
Отдельно стоит сказать про голос. Синтез речи и пения — принципиально разные задачи. Обычный TTS только произносит текст, а вокальная модель должна одновременно попадать в ноты, соблюдать ритм, передавать эмоциональную окраску и удерживать дыхание на нужных слогах. Именно поэтому ранние нейронки пели так неестественно, они решали эти задачи последовательно, а не в комплексе. Современные архитектуры обрабатывают все параллельно, и именно это дает такой качественный скачок в звуке.
Не менее важен вопрос, откуда берутся данные для обучения. Модели, которые опираются на размытое и некачественное аудио, выдают соответствующий результат: глухой звук, нечеткие согласные, размытый ритм. Коммерческие инструменты обучались на студийных записях с хорошим динамическим диапазоном. Именно поэтому одни сервисы звучат как студийный трек, а другие похожи на демо с диктофона. Разница в качестве данных хорошо слышна невооруженным ухом.
Обзор инструментов: лучшая нейросеть для создания музыки
Рынок музыкальных нейросетей вырос настолько быстро, что сориентироваться в нем с первого взгляда непросто. Одни сервисы заточены под полноценные песни с вокалом, другие делают упор на инструментальные саундтреки или работу с атмосферой. У каждого свои сильные стороны, и выбор зависит от конкретной задачи. Ниже представлены четыре инструмента, которые я считаю наиболее показательными.
Suno AI
Этот популярный сервис для генерации полноценных песен умеет создавать трек под ключ, в том числе текст, вокал, аранжировку. Достаточно сделать короткое описание: жанр, настроение, тема и через несколько секунд получаешь готовую композицию длиной до четырех минут. Это и есть главное преимущество Suno перед конкурентами: скорость и полнота результата.
Модель работает с английским языком лучше всего, но начиная с четвертой версии справляется и с русскими текстами. Голос звучит плавно и естественно, без роботизированных артефактов, которые были заметны в ранних версиях. Бесплатный план дает 50 кредитов в день, это примерно 10 треков, что вполне хватает для первых экспериментов.
Интерфейс у Suno намеренно упрощен. Есть два режима: автоматический, где вы пишете только общую идею, и расширенный Custom Mode, где можно загрузить свой текст и задать Style Prompt. Именно такой режим я рекомендую использовать с самого начала, в нем контроль над результатом несопоставимо выше. Плюс можно управлять структурой через специальные теги в тексте: [verse], [chorus], [bridge].
Главный минус Suno в ограниченной работе со звуком после генерации. Загрузить трек на доработку внутри сервиса нельзя, только скачать и открыть во внешнем редакторе. Для тех, кто хочет гибко управлять балансом инструментов или менять партии, это неудобство. Тем не менее для большинства задач Suno остается лучшим выбором среди нейросетей для создания музыки.
Udio
Нейронка делает ставку на качество звука и реалистичность голоса. Если Suno берет скоростью и универсальностью, то Udio выигрывает детализацией. Здесь более тонкая работа с тембром, лучше передается эмоциональная окраска вокала, и общая студийность выше. Когда я сравнивал одни и те же тексты в обоих сервисах, треки из Udio чаще звучали так, будто над ними поработал реальный звукорежиссер.
Сервис позволяет генерировать по 30 секунд и склеивать фрагменты в более длинный трек через функцию Extend. Это неудобнее по сравнению с Suno, где трек создается целиком, но зато дает больше контроля над структурой и темпом развития песни. Можно аккуратно выстроить переход от куплета к припеву, следя за каждым фрагментом отдельно.
Udio хорошо справляется с нестандартными жанрами: джаз, фьюжн, этническая музыка, эмбиент. Там, где Suno иногда скатывается в усредненный поп-звук, Udio сохраняет нужный стиль. Бесплатный тариф поддерживает до 10 генераций в день, это скромнее, чем у конкурента. Зато каждая генерация выдает два варианта на выбор.
MusicLM от Google
Это исследовательский проект Google, открытый для широкой публики через платформу MusicFX в рамках сервиса AI Test Kitchen. Его сильная сторона в генерации по описанию атмосферы. Можно задать что-то вроде «тихий вечер у камина, джаз с фортепиано и контрабасом» и модель передаст именно это ощущение, а не просто подберет похожий жанр из своего каталога.
MusicLM создает только инструментальную музыку без вокала. Это ограничение, если нужна песня, но явный плюс, если нужен фоновый саундтрек для видео, подкаста или рилса. Обучение модели проходило на одном из самых больших аудиодатасетов в истории. Это обеспечивает стабильное качество и широкий диапазон стилей. Отдельный бонус в том, что интерфейс MusicFX поддерживает режим реального времени, где звук меняется прямо при вводе.
Главный минус MusicLM — невозможно скачать результат в высоком качестве без дополнительных инструментов браузера. Это исследовательский прототип, а не полноценный продукт, поэтому ряд удобных функций там попросту не предусмотрен. Тем не менее для быстрой генерации атмосферного фона это один из лучших бесплатных вариантов.
AIVA
Пожалуй, это один из старейших и самых профессиональных инструментов в нише музыкального ИИ. Сервис заточен под создание саундтреков для кино, игр и рекламы. Здесь можно задать тональность, темп, инструментальный состав и получить полноценную оркестровую или электронную партитуру. Именно AIVA чаще других музыкальных нейронок используется в коммерческих проектах.
AIVA предоставляет возможность экспортировать MIDI-файлы и это ее главное преимущество перед конкурентами. MIDI позволяет загрузить результат в любую DAW: FL Studio, Ableton, Logic Pro и редактировать каждую ноту вручную. Это уже серьезный рабочий инструмент для музыканта, а не просто генератор для развлечения.
Бесплатный план позволяет создавать три трека в месяц с лицензией на некоммерческое использование. Платные тарифы стартуют от €11/мес. и полностью снимают ограничения на количество треков и коммерческое использование. AIVA также обучает персонализированные модели на основе загруженных примеров, но эта функция доступна только на старших тарифах.
Инструкция: создать песню с помощью ИИ за 4 шага
Покажу весь процесс на примере работы в Suno AI — самом доступном и функциональном сервисе для тех, кто делает это впервые. Принцип тот же, что и у конкурентов, только интерфейс немного отличается. Весь цикл от идеи до готового файла занял у меня около 20 минут.
Шаг 1. Написание текста
Начну с текста, потому что именно он задает характер всему треку. Если использовать встроенный генератор Suno, достаточно написать тему и жанр, модель сама придумает слова. Но контроль над результатом в этом случае будет минимальный, ведь вы не знаете заранее, что именно окажется в куплете и припеве, и нередко получаете нечто клишированное.
Лучший вариант — написать текст заранее с помощью ChatGPT или другого языкового ИИ. Задача при этом сводится к составлению хорошего промпта. Пример рабочего запроса: «Напиши текст поп-рок-песни о человеке, который уезжает из родного города. Структура: куплет 1 (4 строки, наблюдения за прощанием), куплет 2 (4 строки, воспоминания), припев (4 строки, эмоциональный, повторяется дважды), бридж (2 строки, надежда на возвращение). Тон: светлая грусть. Рифмовка: ABAB. Без банальных рифм».
Получив текст, вставляю его в поле Custom Lyrics в Suno. Модель строит вокальную партию поверх введенных слов, сохраняя структуру и слоговое ударение, если текст написан хорошо. Стоит заранее проверить каждую строку вслух, поскольку неудобные для произношения фрагменты вокальная модель тоже будет петь неловко.
Еще одна полезная возможность — управление структурой через теги прямо внутри текста. Suno понимает разметку вида [Verse 1], [Chorus], [Bridge], [Outro]. Это позволяет явно указать, где начинается припев, где инструментальный проигрыш, а где финал. Без разметки модель расставляет все сама, поэтому результат не всегда совпадает с ожиданиями.
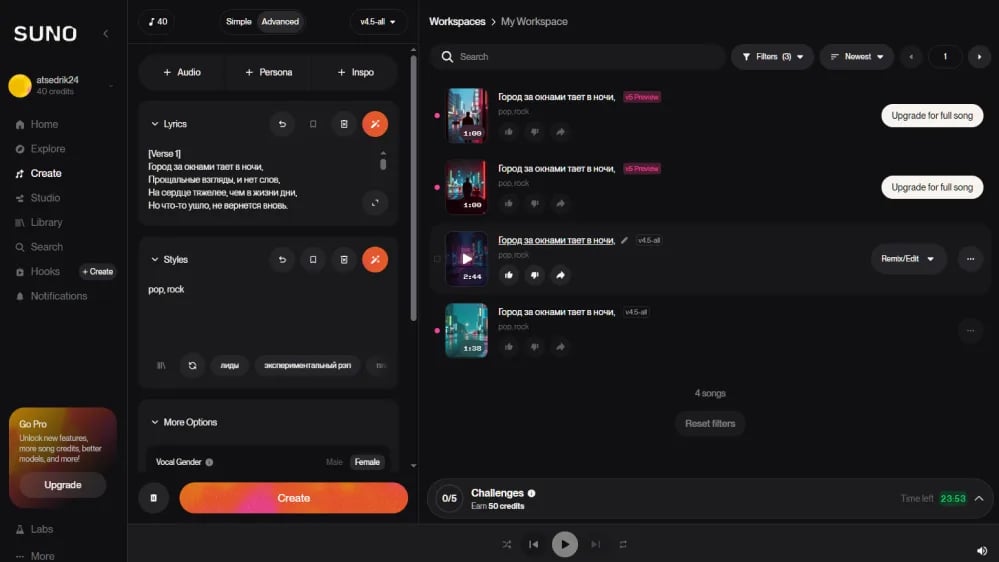
Один из частых вопросов: что лучше короткий или длинный текст? На практике оптимально около 16–24 строк для трека длиной 2,5–3 минуты. Слишком короткий текст модель иногда повторяет по кругу без изменений, слишком длинный не успевает полностью спеть, обрезая финал. Хороший ориентир: один куплет — 4 строки, один припев — 4 строки, итого для полноценной структуры нужно около 20 строк.
Шаг 2. Выбор жанра и стиля (Style Prompt)
Style Prompt — это текстовое описание звука, который я хочу получить. Здесь чем конкретнее, тем лучше. Если писать просто «поп» получится слишком размыто. Лучше: «indie pop, мягкий женский вокал, акустическая гитара, легкая перкуссия, теплый микс, без электронных элементов». Suno воспринимает такие описания буквально, работая с ними как с набором параметров.
Ритм и темп тоже задаются текстом: «uptempo», «slow ballad», «120 bpm groove». Некоторые пользователи указывают конкретных исполнителей как стилистический ориентир: «в стиле Radiohead» или «как Земфира». Suno учитывает эти маркеры при выборе звука, хотя прямого копирования не происходит, модель лишь ориентируется на характерные черты жанра и эпохи.
Я рекомендую экспериментировать со Style Prompt итерационно. Начните с базового описания, послушайте результат, отметьте, что не совпало с ожиданием, скорректируйте одну-две детали. Жанр влияет не только на звук, но и на то, как модель интерпретирует текст, одинаковый куплет прозвучит по-разному в рок-аранжировке и в электронном эмбиенте.
Шаг 3. Генерация и выбор лучшего варианта
После нажатия на кнопку Create сервис выдает два варианта трека. Слушаю оба, сравниваю интонацию вокала, качество аранжировки, соответствие заданному стилю. Отмечаю, как модель интерпретирует эмоциональный тон. Иногда она выбирает верный жанр, но неверное настроение.
Если ни один вариант не устраивает, создаю еще раз. Каждый запуск дает новый результат — это фундаментальное свойство генеративных моделей. Стоит немного менять Style Prompt между попытками, убрать одно слово, добавить другое. Даже небольшие правки существенно меняют характер результата. Обычно за три-четыре попытки нахожу вариант, который можно брать в работу.
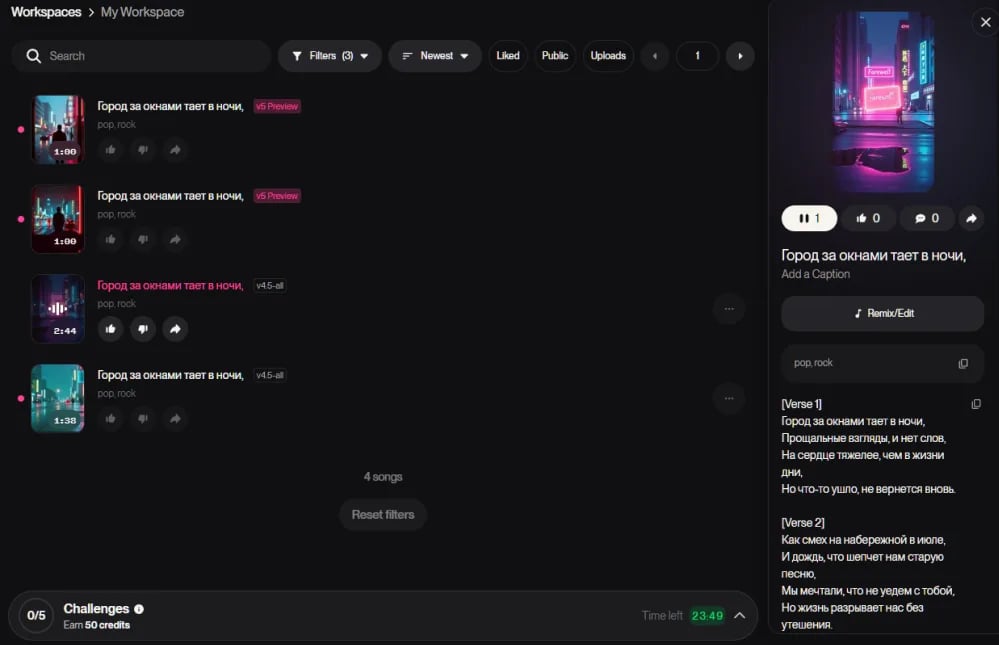
Полезная хитрость: если понравился вокал одного варианта, но не понравилась аранжировка, то можно попробовать функцию Remaster, которая перегенерирует звук, сохраняя вокальную партию. Не всегда работает идеально, но иногда дает именно тот баланс, который нужен.
Шаг 4. Постобработка и скачивание
Готовый трек скачивается прямо с платформы в формате MP3 со стандартным качеством 128–192 кбит/с. Если нужен более высокий контроль над звуком, аудиофайл открываю в редакторе Audacity, Adobe Audition или GarageBand. Там можно отрегулировать громкость, добавить реверб на вокал, срезать лишние частоты в низах или верхах.
Для тех, кто не хочет тратить время на ручное сведение, есть онлайн-мастеринг: LANDR, eMastered, Matchering. Загружаете MP3, сервис автоматически выравнивает уровни, добавляет компрессию, лимитер, трек звучит заметно собраннее. Весь процесс занимает пару минут и ничего не стоит на бесплатном тарифе.
Некоторые идут дальше, накладывая живой вокал поверх сгенерированной инструментальной подложки. Для этого в Suno есть режим Instrumental, который генерирует трек без голоса. Получается интересный гибрид, живое исполнение на фоне ИИ-аранжировки. Именно в таком формате нейросетевые инструменты чаще всего используют профессиональные музыканты, как быструю основу для собственных идей.
Если цель — разместить трек на стриминговых платформах, стоит позаботиться о форматировании. Spotify и Apple Music требуют WAV или FLAC с битрейтом не ниже 44,1 кГц/16 бит. MP3, который выдает Suno, для этого не подходит напрямую. Решение простое, нужно конвертировать MP3 в WAV через любой бесплатный конвертер, а затем запустить мастеринг. После этого файл технически готов к загрузке через дистрибьютора DistroKid, TuneCore или аналоги.
Как создать песню с помощью нейросети бесплатно и без ограничений
Большинство популярных сервисов работают по freemium-модели: базовый доступ бесплатный, но с лимитами на количество генераций и запретом на коммерческое использование. Разберем, что конкретно предлагает каждая платформа на бесплатном тарифе, и как выжать из этого максимум.
Вот актуальные условия по основным инструментам:
- Suno AI. 50 кредитов в день. Каждая генерация стоит 5 кредитов, то есть около 10 треков в сутки. Треки с водяным знаком, коммерческое использование запрещено;
- Udio. 10 генераций в день по 30 секунд каждая. Скачивание доступно, водяного знака нет, но монетизация на бесплатном плане под вопросом;
- MusicFX. Без явных лимитов на количество генераций, только через веб-интерфейс, без API. Скачивание через браузерные инструменты;
- AIVA. 3 трека в месяц на некоммерческой лицензии. Экспорт в MP3, MIDI недоступен на бесплатном плане;
- MusicGen. Опенсорсный, без лимитов при локальной установке. Требует GPU и базовых навыков работы с Python.
Несколько советов по работе в рамках бесплатных тарифов. Во-первых, стоит зарегистрироваться сразу на нескольких платформах и чередовать их в течение дня. Это даст больше попыток без оплаты. Во-вторых, Suno при первой регистрации иногда начисляет дополнительные бонусные кредиты, стоит этим воспользоваться до того, как перейти на обычный ритм.
Еще один рабочий прием, использовать Google Colab для запуска опенсорсных моделей без локальной установки. MusicGen от Meta отлично работает через Colab-ноутбуки, которые выложены в открытом доступе на GitHub. Бесплатный GPU в Colab позволяет генерировать треки длиной до 30 секунд без каких-либо ограничений на количество. Качество несколько ниже, чем у Suno, но зато полная свобода.
Создать песню с помощью ИИ бесплатно для коммерческого использования сложнее. Большинство сервисов запрещают монетизацию на бесплатном плане. Suno разрешает коммерческое использование только на тарифе Pro. AIVA на платном тарифе полностью передает права пользователю. Опенсорсные модели в этом плане свободнее, лицензии у MusicGen и Stable Audio Open, как правило, допускают коммерческое использование при соблюдении условий Attribution.
Стоит отдельно упомянуть Stable Audio Open — опенсорсную модель от Stability AI. Она специализируется на коротких звуковых петлях и текстурах, но при правильном подходе из нее можно собрать полноценный инструментальный трек. Модель доступна на Hugging Face, запускается локально или через бесплатные облачные среды.
Для тех, кто хочет работать с голосом отдельно от аранжировки, есть еще один бесплатный инструмент — Bark от Suno, не стоит путать его с основным сервисом. Это опенсорсная модель синтеза речи и пения, которую можно запустить локально. Bark хуже справляется с мелодикой, чем полноценный Suno, но дает полный контроль над голосом, поддерживает русский язык лучше многих коммерческих аналогов. Это хороший вариант, если нужно быстро озвучить написанный текст без оплаты подписки.
Текст для трека: как заставить нейросеть написать песню
Написание текста с помощью ИИ — отдельная задача, которую стоит решать внимательно. Плохо составленный промпт дает общие, безликие слова. Хороший промпт выглядит как конкретный, образный, структурированный текст, из которого получается настоящая песня. Разберем, как добиться второго результата.
Первое, что нужно сделать — задать структуру, например, два куплета, бридж, припев, финальный куплет. Без этих вводных текст окажется просто набором строф без внутренней логики, что сделает работу вокальной нейросети непредсказуемой.
Второе — конкретные образы вместо абстрактных эмоций. Языковые модели склонны к штампам, по типу «сердце разбито», «ты ушла и я один». Хорошие тексты работают иначе, они показывают, а не называют. Попросите модель описать конкретную сцену, она даст вам куда более живые строки. Пример из практики: вместо «я скучаю по тебе», будет «твоя кружка до сих пор стоит на полке».
Третье — метрика. Каждая строка должна иметь примерно одинаковое количество слогов, это критично для вокальной партии. Если в одном куплете строки по 8 слогов, а в другом по 12, нейросеть будет либо торопиться, либо непривычно растягивать слова. Стоит явно написать в промпте: «строки по 8–9 слогов».
Несколько важных приемов при составлении промптов для ИИ для создания песен:
- Указывайте конкретные образы, а не абстрактные эмоции. «Пустой перрон в пять утра» лучше, чем «грусть расставания».
- Просите избегать клише. Языковые модели склонны к штампам, это нужно явно ограничивать в промпте.
- Задавайте метрику. Укажите, что каждая строка должна иметь примерно одинаковое количество слогов, это критично для вокальной партии.
- Используйте итерации. Попросите переписать слабые строки, сохранив сильные. Это работает лучше, чем генерировать все заново.
- Проверяйте текст вслух перед загрузкой в сервис. Если строка неудобно произносится, то вокальная модель тоже с ней намучится.
- Используйте теги структуры прямо в тексте. [Verse 1], [Chorus], [Bridge], Suno и Udio их понимают, применяя их при аранжировке.
Еще один рабочий подход — написать текст самому, а потом попросить языковую модель его улучшить: «Вот черновик текста песни. Улучши метрику, рифмы, сохранив смысл и образы. Не меняй структуру.» Это позволяет сохранить авторский голос, но избавиться от технических слабостей. Именно в таком режиме ИИ работает наиболее точно, как редактор, а не как автор.
Однако разные языковые модели дают разные результаты на одинаковом промпте. ChatGPT, Claude, Gemini — у каждого свой стиль. Стоит попробовать несколько вариантов и взять лучшие строки из каждого. Финальный текст можно скомпилировать вручную. Это занимает несколько минут, но дает заметно более интересный результат, чем любой одиночный запрос.
Отдельно стоит поговорить о русскоязычных текстах. Большинство вокальных нейронок обучались преимущественно на английском, поэтому русский текст иногда звучит с акцентом или неверными ударениями. Чтобы минимизировать эту проблему, стоит расставлять ударения вручную через заглавные буквы: «я ухожУ в рассвЕт». Suno и Udio частично учитывают такую разметку и ставят ударение правильнее.
Еще один прием для работы с русскоязычным текстом заключается в транслитерации отдельных слов. Если модель упорно неправильно произносит конкретное слово, попробуйте написать его латиницей так, как оно звучит. Например, «Moskva» вместо «Москва». Звучит странно в тексте, но нейронка иногда интерпретирует такую запись как прямую фонетическую инструкцию, произносит слово чище. Это экспериментальный прием, работающий не всегда, но стоит иметь его в арсенале.
Сравнение возможностей музыкальных нейросетей
Прежде чем переходить к таблице, скажу несколько слов о том, по каким параметрам вообще имеет смысл сравнивать музыкальные нейросети. Качество вокала важно для тех, кто хочет получить готовую песню с лирикой. Длина трека определяет, можно ли создать полноценную композицию за один запрос или придется склеивать фрагменты.
Поддержка русского языка — отдельный, непростой вопрос, большинство моделей обучалось преимущественно на английских данных, и это слышно. Стоимость подписки, конечно, играет роль при выборе для регулярного использования.
Принцип, которым я руководствуюсь при выборе: если нужна быстрая полноценная песня — Suno, если важно качество звука и реализм голоса — Udio, если нужен инструментальный фон для видео — MusicLM или AIVA, если нужен полный контроль без ограничений — MusicGen локально.
| Сервис | Качество вокала | Длина трека | Русский язык | Бесплатный план | Коммерческое использование |
|---|---|---|---|---|---|
| Suno AI | Высокое | До 4 минут | Базовая поддержка | 50 кредитов/день | Только на Pro (от $10/мес.) |
| Udio | Очень высокое | До 30 сек/расширение | Ограниченная | 10 генераций/день | На платном тарифе |
| MusicLM | Нет вокала | До 70 секунд | Не поддерживается | Без явных лимитов (веб) | Не для коммерции |
| AIVA | Нет вокала | До 5 минут | Не поддерживается | 3 трека/месяц | На платном тарифе (от €11/мес.) |
| MusicGen | Нет вокала | До 30 секунд | Ограниченная | Опенсорс/локально | Зависит от лицензии модели |
Несколько наблюдений по итогам личного тестирования. Suno стабильнее всех справляется с заданной структурой, куплеты и припевы оказываются там, где ожидаешь. Udio дает лучший звук, но иногда игнорирует указанную структуру, строит трек по своей логике. MusicLM лучше всех передает атмосферу, но не масштабируется до полноценной песни. AIVA незаменима, если результат нужно дорабатывать в DAW.
FAQ
Кому принадлежат авторские права на музыку от ИИ?
Это пока открытый вопрос в большинстве юрисдикций. В России и США суды не признают ИИ автором, произведение без человека-создателя не защищается авторским правом. На практике это означает, что треки, сгенерированные нейросетью только по общему промпту, находятся в правовой серой зоне.
Если вы пишете текст, задаете детальные инструкции, редактируете результат, то аргументов в пользу вашего авторства больше. Каждый сервис описывает условия в своих Terms of Service: Suno, например, передает права пользователю на платных тарифах и заявляет, что не претендует на владение вашими треками.
Можно ли создать песню с помощью нейросети бесплатно для коммерческого использования?
Да, но с оговорками. На бесплатных тарифах большинство сервисов запрещают монетизацию. Опенсорсные модели по типу MusicGen от Meta, Stable Audio Open, как правило, позволяют коммерческое использование при соблюдении условий Attribution. Перед публикацией трека стоит внимательно читать лицензионное соглашение конкретного сервиса, потому что условия периодически обновляются. Использование на платном тарифе почти всегда снимает коммерческие ограничения.
Какая нейросеть для создания музыки лучше всего поет на русском языке?
Лучший результат с русским текстом показывает Suno AI версии 4. Udio тоже справляется, но хуже обрабатывает интонации и ударения, особенно в словах с нестандартным положением ударного слога. Если качество русского вокала критично для задачи, рекомендую тестировать оба сервиса на одном тексте и выбирать лучший вариант вручную. Помогает также расстановка ударений заглавными буквами прямо в тексте.
Как добиться максимально чистого звука при генерации?
Несколько рабочих советов. Первое — пишите конкретный Style Prompt: указывайте «студийное качество», «чистый микс», «без дисторшна», если это важно для результата. Второе — избегайте слишком перегруженных описаний с большим количеством инструментов: чем больше элементов вы укажете, тем хаотичнее может получиться аранжировка. Третье — прогоните трек через бесплатный онлайн-мастеринг-сервис вроде LANDR или eMastered после генерации. Это заметно улучшает звук даже без ручной работы над сведением.
Можно ли загрузить свою мелодию и «достроить» ее нейросетью?
Да, часть сервисов это поддерживает. Udio позволяет загрузить аудиофайл и использовать его как основу для генерации. В Suno эта функция появилась в версии 4. Можно загрузить мелодическую идею, попросить модель развить ее в полноценный трек. Это один из самых интересных сценариев использования: набросал мотив на гитаре, загрузил, получил аранжировку. Качество результата зависит от чистоты исходной записи, чем меньше фонового шума, тем лучше модель считывает мелодию.
Музыкальные нейросети за последние два года прошли огромный путь: от экспериментальных демонстраций до рабочих инструментов, которыми пользуются продюсеры, блогеры, обычные слушатели. Порог входа стал настолько низким, что попробовать стоит любому, даже если вы никогда не держали в руках гитару и не знаете, что такое тактовый размер.
Главный совет — не останавливаться на первой попытке. Качество результата напрямую зависит от того, насколько точно сформулирован запрос. Потратьте время на текст, поработайте над Style Prompt, попробуйте разные сервисы на одном и том же материале. Разница между небрежным промптом и продуманным — это разница между треком, который хочется выключить, и треком, который хочется переслушать.
Если вас интересует, как создать песню с помощью нейросети под конкретную задачу: коммерческое видео, личный проект или просто ради интереса, то большинство перечисленных платформ дают бесплатный доступ, которого вполне хватит для первых экспериментов. Начните с Suno, попробуйте Udio, сравните результаты. Процесс затягивает.
Если вы уже работали с каким-то из этих сервисов или нашли интересный вариант, который я не упомянул, пишите в комментариях. Обмен конкретным опытом здесь особенно ценен, поскольку сервисы обновляются быстро и то, что работало месяц назад, может работать иначе уже сегодня.
*Meta — организация признана экстремистской, и ее деятельность запрещена на территории РФ.

Комментарии к статье
Можете посоветовать пару промптов, чтобы вокал звучал естественно на русском?
1 ответ
Я пробовала перегенерить еще раз, добавляла в начале "natural russian vocal", "clear russian pronunction" и получалось прям хорошо. Кстати,если поменьше задавать эмоций, то чаще сразу будет норм, без искусственного звука
а возможно использовать собственный голос?