Что такое ИИ токены: гайд по «кирпичикам» нейросетей и их стоимости

В этой статье я разбираю, что такое ИИ токены, как они устроены и почему именно от них зависит стоимость работы с любой нейросетью. Заодно расскажу, как считать их самостоятельно и где разработчику взять пробный доступ к моделям без лишних трат.
Без понимания этой единицы невозможно ни прикинуть бюджет на ИИ-проект, ни выстроить нормальный промпт, ни уложиться в контекстное окно. Один неаккуратный цикл в коде — и за ночь сгорает месячная подписка, один лишний абзац в системном промпте — и каждый запрос дорожает на четверть.
В материале последовательно поднимаются такие вопросы:
- как нейросеть «видит» текст и зачем ему вообще токены;
- как работает токенизация и алгоритм BPE;
- почему за токены берут деньги и как формируется тарификация за 1 млн токенов;
- что такое контекстное окно и лимиты запросов;
- какими приемами можно сократить расходы на API;
- где взять пробный доступ к моделям и бесплатные токены.
В конце — сравнительная таблица с количеством токенов в популярных текстах и блок с частыми вопросами.
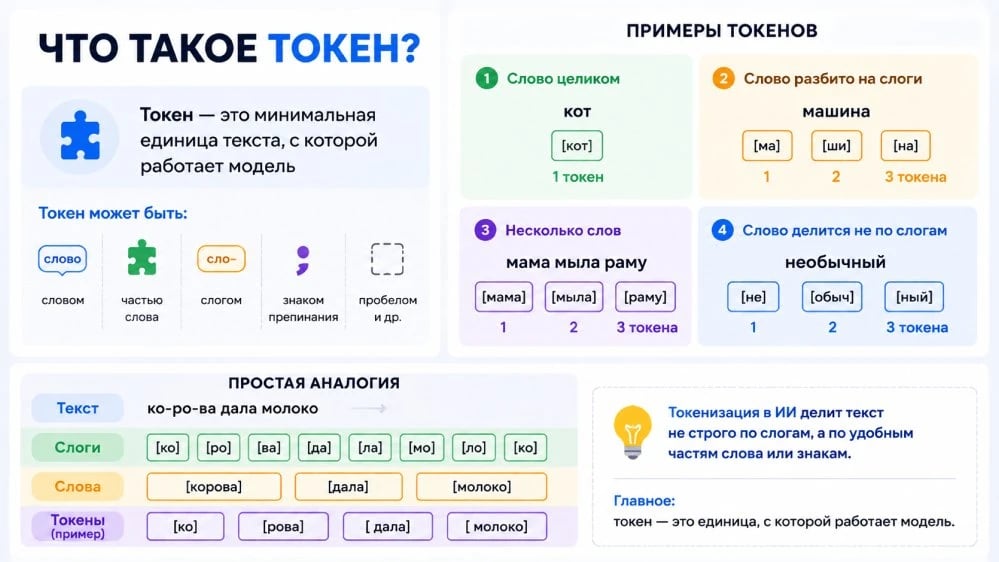
Токен — это «слог» в языке нейросети
Начну с главного. Токен в ИИ — это, простыми словами, минимальная единица текста, с которой работает модель. Не буква, не слово, не предложение, а нечто среднее: фрагмент длиной обычно в 2–5 символов, который алгоритм научился узнавать как самостоятельный «кусочек смысла».
Чтобы было понятнее, приведу аналогию. Представьте, что вы изучаете иностранный язык. Сначала запоминаете отдельные буквы, потом слоги, потом целые слова и устойчивые выражения.
Нейросеть устроена похоже: для нее «слоги» — это токены, и из них собирается все остальное. Слово «продуктивность» она вполне может разбить на «прод», «укт», «ивн», «ость», а слово «кот» — оставить целиком, потому что оно встречается часто и достаточно короткое.
Зачем такие сложности? Дело в компромиссе между двумя крайностями:
- если работать только со словами, словарь модели разрастется до миллионов словоформ: «кот», «кота», «коту», «котом», «коты», «котов» — и так почти у каждого русского существительного;
- если использовать отдельные символы, последовательности станут слишком длинными, и модели придется «помнить» гораздо больше шагов, чтобы уловить смысл.
Токены — это золотая середина: достаточно компактно, чтобы не раздувать словарь, и достаточно осмысленно для определения структуры языка моделью. Типичный размер словаря у современных моделей — от 50 до 200 тысяч уникальных токенов. Этого хватает, чтобы аккуратно покрыть десятки языков, эмодзи, программный код и редкие термины.
Интересно, что некоторые токены вообще не несут смысла для человека. Например, в словаре GPT-моделей можно найти фрагменты вроде «ственно» или «cially» — кусочки, которые часто встречаются в текстах как окончания, но сами по себе ничего не значат. Это нормально: модель работает не с лексикой, а со статистикой.
Важно понимать: токены не равны буквам, не равны слогам в лингвистическом смысле и не равны словам. Это статистические единицы. Они получены из огромного корпуса текстов методом подсчета частот, и для каждой модели — OpenAI, Anthropic, Google Gemini — собственный словарь токенов.
Поэтому одна и та же фраза у GPT-4o и Claude 3.5 разбивается по-разному и даст чуть разное количество токенов. Сравните основные нюансы в таблице:
| Особенность | Что это значит на практике |
|---|---|
| Пробелы и знаки препинания считаются | Точка, запятая, ведущий пробел — отдельные токены |
| Регистр имеет значение | «Red», « Red» (с пробелом) и «red» — три разных токена |
| Язык влияет на расход | Русский расходует в 1,5–2 раза больше токенов, чем английский |
| У каждой модели свой словарь | Одна фраза у GPT и Claude разобьется по-разному |
| Код и спецсимволы — отдельная история | Скобки, табуляции, фигурки в JSON — все это токены |
Еще одно полезное наблюдение: чем чаще токен встречается в обучающем корпусе, тем меньше у него внутренний числовой идентификатор. Самые распространенные знаки препинания и короткие служебные слова получают совсем маленькие ID, а редкие технические термины — большие. Это техническая деталь, но она хорошо объясняет, почему нейросеть так быстро ориентируется в «обычном» тексте и спотыкается на узкоспециальной лексике.
Как из текста получается математика: процесс токенизации
Теперь разберем техническую сторону: как именно происходит разбиение текста. Процесс называется токенизация (Tokenization), и за него отвечает специальный модуль модели — кодировщик (Encoder). Его задача — превратить понятный нам текст в последовательность чисел, потому что нейросеть оперирует только числами.
Путь текста от запроса до ответа выглядит так:
- Пользователь вводит запрос (промпт).
- Кодировщик разбивает текст на токены по заранее обученному словарю.
- Каждому токену присваивается уникальный числовой идентификатор (ID).
- ID превращается в векторное представление — длинный массив чисел, который описывает «смысл» токена в многомерном пространстве.
- Эти векторы попадают в латентное пространство модели, где веса модели обрабатывают их и предсказывают следующий токен.
- Результат декодируется обратно в текст и возвращается пользователю.
Весь этот путь занимает доли секунды, но именно на этих шагах формируется и качество ответа, и итоговый счет за API. Если в кодировщике что-то пошло не так — например, в промпт попали редкие символы или нестандартная кодировка, — модель может «увидеть» текст совсем не так, как задумал автор.
Алгоритм BPE: как строится словарь
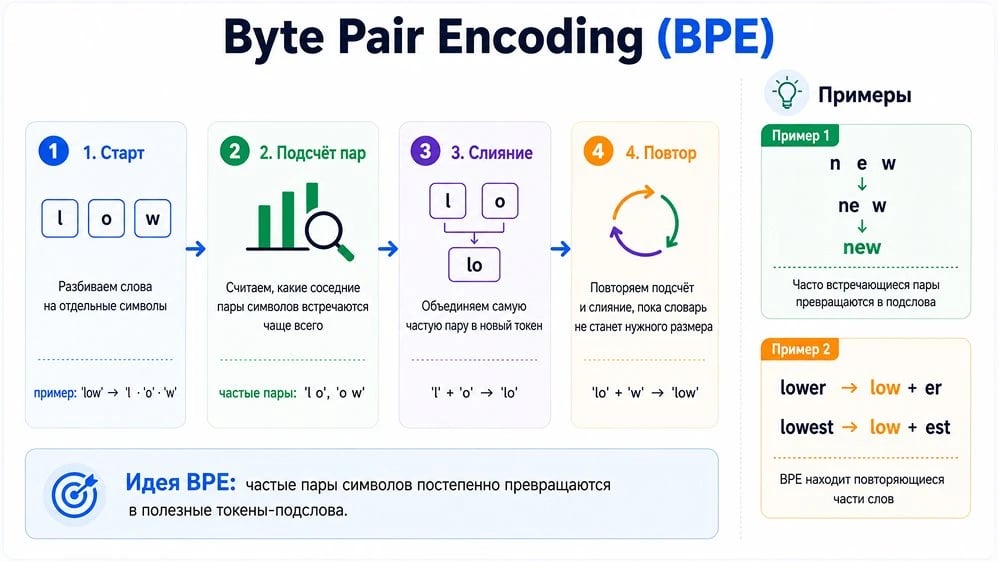
Самый популярный алгоритм построения словаря токенов называется Byte Pair Encoding (BPE). Его суть простая, и мне кажется красивой.
Берется огромный текстовый датасет, на старте каждая буква считается отдельным токеном. Дальше алгоритм идет в цикл: находит самую частую пару соседних символов и склеивает ее в новый токен. Потом снова считает частоты и снова склеивает самую частую пару. И так тысячи или миллионы раз, пока словарь не достигнет нужного размера — обычно от 30 до 200 тысяч токенов.
Покажу на маленьком примере. Допустим, у нас есть две фразы: «привет, мир» и «ветхий дом». Логика алгоритма пошагово:
| Шаг | Что происходит | Результат |
|---|---|---|
| 1 | Пара «в»+«е» встречается дважды (в «привет» и «ветхий») | Склеиваем в токен «ве» |
| 2 | Пара «ве»+«т» тоже встречается дважды | Получаем токен «вет» |
| 3 | Остальные пары единичные | Для крохотного корпуса процесс закончен |
На реальных триллионах символов все происходит точно так же, только шагов гораздо больше и финальные токены превращаются в осмысленные кусочки слов. Любопытный факт: подобный словарь для крупной LLM обучается на специальных кластерах в течение нескольких часов или дней — это отдельный технологический этап перед обучением самой нейросети.
Другие алгоритмы
Помимо BPE, существуют родственные алгоритмы. Их основные отличия удобнее свести в таблицу:
| Алгоритм | Принцип работы | Где применяется |
|---|---|---|
| BPE | Слияние самой частой пары соседних токенов | GPT, Llama, большинство LLM |
| WordPiece | Слияние по критерию максимального правдоподобия корпуса | BERT и его производные |
| SentencePiece | Работает с «сырым» текстом, включая пробелы | Языки без пробелов (японский, китайский) |
| Byte-level BPE | Улучшенный BPE на уровне UTF-8 байтов | Поддержка любых символов и эмодзи |
| Unigram LM | Вероятностное удаление редких токенов из большого словаря | Альтернатива внутри SentencePiece |
Для большинства современных LLM (Large Language Models) от OpenAI и Anthropic используется именно BPE или его byte-level версия. У Google в семействе Gemini применяется свой вариант на основе SentencePiece, у Llama-моделей — собственный токенизатор, тоже близкий к BPE. Несмотря на разницу в деталях, все они принадлежат одному семейству subword-методов.
После того как токены получены, в дело вступает обработка естественного языка (NLP) на уровне глубокого обучения. Модель смотрит не на сами токены, а на их векторы — числовые представления, отражающие семантику.
Слова «кошка» и «котенок» окажутся рядом в этом пространстве, а «кошка» и «трактор» — далеко. Именно так нейросеть «понимает», что слова связаны по смыслу, хотя в исходном тексте они выглядят совершенно по-разному.
Эта геометрия смыслов — одна из причин, почему LLM так хорошо обобщают. Даже если модель никогда не видела точную формулировку вашего вопроса, в латентном пространстве она найдет похожие по смыслу примеры и подберет адекватный ответ.
Сколько стоят токены и как формируется цена
А теперь поговорим про деньги. Если вы пользуетесь ChatGPT, Claude или Gemini через подписку, токены работают «под капотом» и вы их не видите. Но как только вы подключаетесь к API ключу и начинаете встраивать ИИ в свой продукт, становится критически важно понимать, что значат токены в ИИ применительно к вашему бюджету и счетам от провайдера.
Все провайдеры тарифицируют использование по одной схеме: цена за 1 млн токенов. При этом отдельно считаются:
- входные данные — все, что вы отправили модели (промпт + история);
- выходные данные — все, что она сгенерировала в ответ.
Выходные токены почти всегда дороже входных — иногда в 2–5 раз. Причина простая: генерация требует больше вычислений, чем чтение. Когда модель читает входной текст, она прогоняет его через сеть один раз. Когда генерирует ответ — повторяет эту процедуру для каждого нового токена отдельно.
Чтобы было понятнее, что значит «миллион токенов» на практике, держите ориентир. Один миллион — это примерно:
- 750 тысяч слов английского текста;
- около 1 500 страниц книги;
- 2–3 часа активной переписки с чат-ботом;
- расшифровка одного часового видео;
- средний роман объемом 350–400 страниц.
Звучит как много, но при регулярном использовании в бизнес-задачах такой объем расходуется буквально за несколько дней. Простой пример: чат-бот техподдержки на 200 диалогов в день с длинной системной инструкцией легко съедает миллион токенов за неделю. А аналитический агент, который обрабатывает входящие документы, способен сделать это за пару часов.
Категории токенов в счете
Цена сильно зависит от уровня модели. Условная базовая модель может стоить копейки за миллион токенов, а флагман с продвинутыми рассуждениями — в 10–50 раз дороже. Стоимость генерации напрямую коррелирует с количеством используемых GPU и временем работы.
Отдельная история — токены рассуждения (reasoning tokens), которые появились в новых моделях. Перед тем как выдать ответ, модель «думает про себя», и эти невидимые внутренние шаги тоже тарифицируются. На сложных задачах reasoning может занимать в 3–10 раз больше токенов, чем сам финальный ответ.
Чтобы было нагляднее, я свел типичные категории тарификации в таблицу:
| Категория токенов | Что это | Особенности тарификации |
|---|---|---|
| Входные (input) | Текст промпта и истории диалога | Базовая ставка |
| Выходные (output) | Сгенерированный моделью ответ | В 2–5 раз дороже входных |
| Кэшированные | Повторно используемые части промпта | Скидка 50–90% относительно input |
| Reasoning | Внутренние шаги «размышления» модели | Тарифицируются как output |
| Batch | Отложенная обработка запросов | Скидка до 50% |
| Image / Audio | Картинки и аудио на входе | Считаются по своим коэффициентам |
Еще одна важная деталь — русский язык дороже английского. Из-за особенностей токенизации одно и то же сообщение на русском съедает в 1,5–2 раза больше токенов, чем его английский перевод. Если ваш продукт работает преимущественно с русскоязычной аудиторией, закладывайте этот множитель в бюджет.
Реальный кейс из моей практики: бот, который ежедневно отвечает на 500 вопросов сотрудников на русском, обходился в 4 раза дороже своего англоязычного аналога в международной компании при идентичной логике. После того как мы переписали системный промпт на английский и оставили русским только пользовательский ввод, стоимость снизилась примерно на 35%.
Тренд: рынок дешевеет
Сам рынок при этом стремительно дешевеет. Динамика последних лет впечатляет:
- 2022 год — около 20 долларов за миллион токенов у топовых моделей;
- 2024 год — порядка 2–5 долларов у моделей сопоставимого качества;
- 2026 год — флагманские модели в районе 1–3 долларов, базовые — десятые доли цента.
Тренд продолжается, поэтому фиксировать долгосрочные контракты с провайдерами невыгодно: через полгода условия станут лучше. Параллельно усиливается конкуренция за счет открытых моделей — Llama, Qwen, Mistral, DeepSeek, — которые можно запускать самостоятельно и платить только за инфраструктуру.
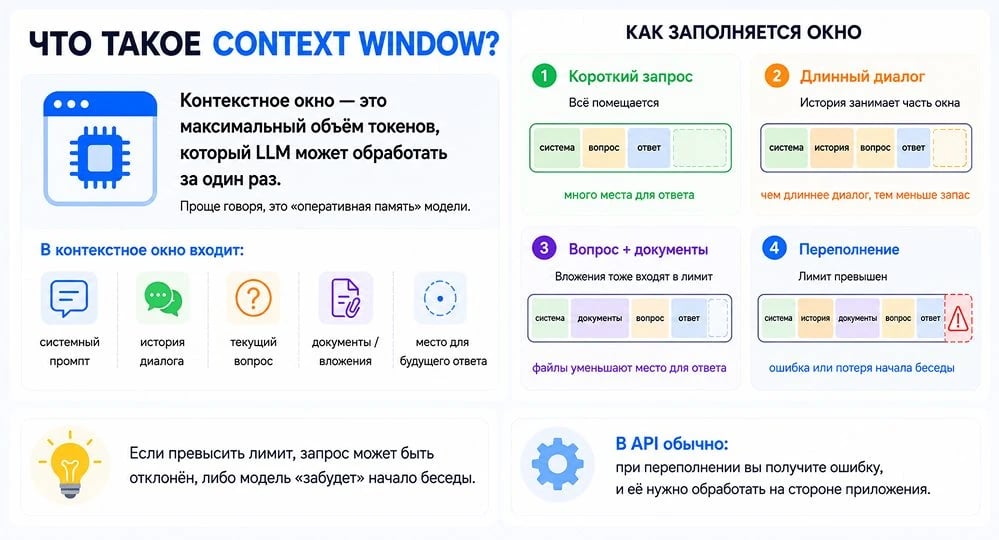
Контекстное окно: сколько модель может «удержать в голове»
Любая LLM ограничена тем, сколько токенов она способна обработать за один раз. Этот лимит называется контекстное окно (Context Window), и он напрямую связан с лимитами токенов в каждом конкретном запросе.
Если объяснять простыми словами, контекстное окно — это «оперативная память» модели. В нее помещается все:
- системный промпт;
- история диалога;
- ваш текущий вопрос;
- прикрепленные документы;
- место для будущего ответа модели.
Превысите лимит — и либо запрос будет отклонен, либо модель «забудет» начало беседы. В большинстве API при переполнении вы получите ошибку, и обрабатывать ее придется на стороне приложения.
Размеры контекстных окон у разных моделей отличаются разительно. Ниже — ориентир по актуальным флагманам:
| Модель | Размер контекстного окна |
|---|---|
| GPT-4o (OpenAI) | ~128 000 токенов |
| Claude 3.5 (Anthropic) | ~200 000 токенов |
| Google Gemini 1.5 Pro | до 1–2 миллионов токенов |
| Llama 3 / Mistral Large | от 32 000 до 128 000 токенов |
| Бюджетные модели старого поколения | 4 000 – 32 000 токенов |
Миллион токенов у Gemini звучит фантастически: туда буквально влезает «Война и мир» целиком, с приложениями и комментариями. Но на практике все не так однозначно.
Чем больше контекст, тем хуже модель «помнит» середину. Этот феномен называется lost in the middle: информация в начале и конце промпта обрабатывается хорошо, а сведения где-то на 60% длины могут банально потеряться. Существуют специальные бенчмарки (например, Needle in a Haystack), которые измеряют этот эффект.
Контекстное окно влияет и на скорость, и на стоимость. Каждый токен в контексте — это деньги и время. Если вы подаете модели полную историю диалога из 50 сообщений каждый запрос, вы платите за нее снова и снова.
Именно поэтому в индустрии активно развивается сжатие контекста — суммаризация старой части диалога, чтобы оставлять в памяти только ключевые факты. Если коротко резюмировать, что значат токены в ИИ с точки зрения контекстного окна, — это одновременно единицы памяти модели и единицы вашего счёта, и каждая из них работает в обе стороны.
- Полная суммаризация всей истории в короткое резюме.
- Скользящее окно: хранить только последние N сообщений + сжатую выжимку остального.
- RAG-подход: вместо истории подгружать только релевантные текущему вопросу фрагменты.
- Гибрид: важные факты — в системный промпт, оперативную переписку — в скользящее окно.
Помимо контекстного окна, есть еще лимиты запросов (Rate Limits). Это ограничения по количеству запросов или токенов в минуту/в день, которые провайдер ставит на ваш API ключ. У бесплатных тиров они жесткие, у платных — гораздо мягче, но все равно конечные.
Типичный сценарий, когда ограничения внезапно становятся проблемой, — массовая миграция данных. Например, обработка архива из десятков тысяч документов: вы упретесь в лимит токенов в минуту задолго до того, как закончится бюджет. Решение — батчинг, очереди и плавная скорость подачи.
Как тратить меньше и получать больше
Расходы на ИИ умеют расти незаметно. Я не раз слышал истории, когда команда подключила API на тестовый период, а через неделю получила счет в несколько тысяч долларов из-за фоновых задач, о которых забыли. Особенно часто это случается на стадии прототипа, когда разработчики экспериментируют, забывают выключить тестовые скрипты, и они продолжают молотить запросы по ночам.
Чтобы такого не было, есть несколько проверенных приемов экономии. Сведу их в таблицу с понятной отдачей по каждому пункту:
| Прием | Что делать | Эффект |
|---|---|---|
| Подбор модели под задачу | Базовая модель для простого, флагман — только для сложного | Экономия в 5–20 раз на рутинных задачах |
| Кэширование токенов | Стабильную часть промпта помечать как кэшируемую | Снижение счета на 30–70% |
| Промпт-инжиниринг | Сокращать формулировки, убирать дубли | До –30% по входным токенам |
| Batch-режим | Отправлять несрочные задачи пакетом | Скидка до 50% |
| Мониторинг и лимиты | Настроить дневной потолок и оповещения | Защита от форс-мажоров |
| Сжатие истории диалога | Суммаризировать старые сообщения | До –80% входных токенов в длинных сессиях |
| Структурированный вывод | Просить JSON вместо свободного текста | Короче ответ — меньше output-токенов |
Расскажу подробнее про пункты, которые работают сильнее всего.
Выбор модели под задачу
Не нужно гонять флагман для исправления опечаток или базовой классификации писем. У каждого провайдера есть линейка: маленькая, средняя, флагман.
Грубое правило — берите минимально достаточную модель, а флагман подключайте только там, где качество критично. Часто бюджетная модель решает 80% задач, а 20% сложных случаев имеет смысл маршрутизировать на старшую.
Такой подход называется model routing и реализуется парой строк кода: классификатор смотрит на входной запрос и решает, какой моделью его обрабатывать. На длинной дистанции эта простая логика дает 3–5-кратную экономию без потери качества.
Кэширование и работа с промптом
Большинство провайдеров умеют запоминать стабильную часть промпта (например, длинную системную инструкцию или базу знаний) и брать за нее в разы меньше денег при повторных запросах. Если у вас один и тот же системный промпт повторяется в каждом обращении — обязательно включайте кэширование токенов.
Технически это работает так: провайдер хранит «слепок» начала вашего промпта в течение нескольких минут или часов. При следующем запросе с тем же префиксом модель не пересчитывает его с нуля, а берет готовое представление из кэша. Отсюда и скидка до 90%.
Параллельно полезно вкладываться в промпт-инжиниринг. Простые правила, которые экономят токены без потери качества:
- убирайте вежливые формулы «пожалуйста», «спасибо», «будьте добры» из системных инструкций;
- заменяйте длинные перечисления примеров на 2–3 самых показательных;
- используйте маркированные списки вместо длинных абзацев;
- выносите повторяющиеся блоки в кэшируемый префикс;
- иногда переписывание промпта с русского на английский сокращает количество токенов почти вдвое, а качество ответа при этом не страдает.
Следите за рынком
Раз в несколько месяцев появляются новые модели с лучшим соотношением цена/качество. То, что сегодня кажется оптимальным, через полгода может стать в три раза дороже аналога. Гибкость и готовность переключаться между провайдерами — серьезное конкурентное преимущество.
Практически это означает, что в коде стоит сразу закладывать абстракцию над провайдером. Идеально — единый интерфейс, за которым может скрываться и OpenAI, и Anthropic, и локальная модель. Переключение в этом случае занимает минуты, а не дни.
Где взять бесплатный доступ и пробные периоды
Хорошая новость для тех, кто только пробует: бесплатные токены ИИ раздают почти все крупные провайдеры. Где-то это разовый бонус при регистрации, где-то — ежемесячный лимит для разработчиков, где-то — открытый доступ к младшим моделям.
Самые популярные варианты получить пробный объем токенов и поэкспериментировать с API:
- OpenAI — исторически давал стартовый кредит при регистрации (условия меняются, проверяйте актуальные);
- Anthropic — бесплатный лимит на тестирование Claude через консоль для разработчиков;
- Google AI Studio — щедрый бесплатный доступ к Gemini-моделям через API ключ, пожалуй, самый дружелюбный вариант для начинающих;
- OpenRouter и аналогичные агрегаторы — периодически раздают тестовые кредиты на десятки моделей сразу;
- Hugging Face Inference API — бесплатный запуск многих открытых моделей с ограничениями по нагрузке;
- локальные модели (Llama, Mistral, Qwen и другие) — можно запускать на собственном железе вообще без оплаты, нужны только GPU или приличный CPU.
Отдельно стоит сказать про образовательные программы. Если вы студент, преподаватель или работаете над open-source-проектом, у многих провайдеров есть гранты на API. Анкеты простые, ответ обычно приходит в течение пары недель, а лимиты на бесплатные токены ИИ в таких программах заметно выше обычных.
Помимо официальных программ, можно искать гранты и кредиты в смежных местах:
- стартап-акселераторы часто включают пакеты от OpenAI и Anthropic как часть программы;
- облачные провайдеры (AWS, Azure, GCP) раздают кредиты на свои AI-сервисы;
- хакатоны и студенческие конкурсы — короткий, но эффективный способ получить разовый доступ;
- участие в beta-программах новых моделей нередко вознаграждается дополнительным лимитом.
Когда я тестирую новую идею, мой стандартный путь такой:
- Прототип — на Google AI Studio (бесплатно).
- Доводка — на платном тарифе у OpenAI или Anthropic.
- Финальный выбор провайдера — по соотношению цены и качества под конкретную задачу.
Такой подход позволяет не платить за обучение и эксперименты, а тратить деньги уже на работающий продукт. Дополнительный бонус — параллельное знакомство сразу с несколькими экосистемами, что потом облегчает миграцию между ними.
Сколько токенов в популярных текстах
Чтобы цифры в тарифах перестали быть абстракцией, я собрал сравнительную таблицу. Она показывает, во сколько токенов превращаются знакомые объемы текста на русском и английском языках.
Цифры приблизительные — у разных моделей разбиение немного отличается, но порядок величин стабилен.
| Тип контента | Объем в словах | Токены (RU) | Токены (EN) |
|---|---|---|---|
| Короткий промпт («Напиши план статьи про токены») | ~6 | ~15 | ~9 |
| Один абзац текста | ~80 | ~180 | ~110 |
| Одна страница А4 | ~300 | ~700 | ~400 |
| Статья среднего объема | ~1 500 | ~3 500 | ~2 000 |
| Глава книги | ~8 000 | ~18 000 | ~10 700 |
| «Маленький принц» (целиком) | ~17 000 | ~38 000 | ~23 000 |
| «Мастер и Маргарита» | ~145 000 | ~330 000 | ~195 000 |
| «Война и мир» | ~560 000 | ~1 300 000 | ~750 000 |
| Часовой подкаст (расшифровка) | ~9 000 | ~21 000 | ~12 000 |
| Декларация независимости США | ~1 300 | — | ~1 700 |
Из таблицы видна та самая «русская наценка»: на одном и том же содержании русскоязычный текст съедает примерно в 1,7 раза больше токенов, чем английский. Если ваш продукт работает с большими корпусами на русском, это нужно закладывать в финансовую модель сразу.
Еще один важный вывод: даже у современных моделей с гигантским контекстом полноценный анализ толстого романа за один запрос — задача нетривиальная. «Война и мир» помещается только в Gemini с миллионным окном, и даже там качество восприятия середины пострадает.
Для серьезной работы с длинными документами все равно нужны разбиение на части, индексация и поиск по релевантным фрагментам — то, что в индустрии называется RAG (Retrieval-Augmented Generation).
Несколько дополнительных бытовых ориентиров, которые удобно держать в голове:
- средний email — 200–400 токенов;
- пост в соцсети — 50–150 токенов;
- техническое задание на 1 страницу — 600–900 токенов;
- юридический договор на 10 страниц — около 7–10 тысяч токенов;
- транскрипт часового совещания — 10–15 тысяч токенов.
Эти числа полезно просто запомнить — они быстро превращают абстрактные «миллионы токенов» в понятные единицы повседневной работы.
FAQ: короткие ответы на частые вопросы
Чем токен отличается от слова или символа?
Токен в ИИ — это, простыми словами, статистическая единица, которую модель получила в процессе обучения на огромном корпусе текстов. Чаще всего он соответствует кусочку слова длиной 2–5 символов. Иногда токен совпадает с целым коротким словом («кот», «и»), иногда — с одним символом или даже одним байтом для редких знаков. Прямой связи с лингвистическими слогами или морфемами у токенов нет.
Почему текст на русском обходится дороже, чем на английском?
Словари большинства популярных моделей строились преимущественно на англоязычных корпусах, и для английского у них самые компактные токены. Кириллица закодирована менее эффективно: одно русское слово в среднем разбивается на большее число токенов, чем его английский аналог. Отсюда увеличение счета примерно в 1,5–2 раза при том же объеме информации.
Что входит в подсчет токенов: только мой текст?
Нет, считается все, что попадает в контекст модели. Это системный промпт, история диалога, ваш текущий запрос, прикрепленные файлы (после конвертации в текст) и сгенерированный ответ.
Как самому посчитать количество токенов в тексте?
У OpenAI есть бесплатный инструмент Tokenizer на их сайте — он показывает разбиение наглядно. Для программной работы существует библиотека tiktoken (модели OpenAI), у Anthropic свой токенизатор, у Hugging Face — универсальные. Все они открытые и работают на любой машине без обращения к API.
Можно ли вообще обойтись без оплаты токенов?
Можно, если запускать открытые модели локально (Llama, Mistral, Qwen и подобные). Тогда вы платите только за электричество и амортизацию своего железа.
Минус — нужна приличная видеокарта или серверная конфигурация, и качество младших открытых моделей все еще уступает топовым коммерческим. Для прототипов и обучения отличный вариант, для продакшна — нужно считать TCO.
Влияет ли формат ответа на расход токенов?
Да, и существенно. JSON с подробными ключами расходует больше токенов, чем компактная структура. Markdown с заголовками и списками — больше, чем сплошной текст. Если задача чисто служебная и ответ не показывается пользователю напрямую, имеет смысл просить модель отвечать максимально лаконично — это прямая экономия выходных токенов.
Заключение
Подытожу. Я разобрал, что такое ИИ токены, как работает токенизация по алгоритму BPE, почему за входные и выходные данные берут разную цену и как сэкономить с помощью кэширования, batch-режима и оптимизации промптов.
Главный совет — относитесь к токенам как к валюте: считайте, бюджетируйте, выбирайте модель под задачу. Рынок быстро дешевеет, инструменты становятся доступнее, и сегодня запустить ИИ-функцию в продукте можно за смешные деньги, если делать это с пониманием экономики.
А как у вас с расходами на ИИ — уже встраиваете нейросети в работу или только присматриваетесь? Делитесь опытом, вопросами и кейсами в комментариях, обсудим вместе.

Комментарии к статье
Еще не встречала такого подробного и простого объяснения! Теперь хоть можно заранее спланировать, сколько токенов потребуется, думала, это что то вроде одного запроса, но они загадачно быстро улетучивались
1 ответ
согласна! я стала замечать у многих сервисов мелькающее слово "токен", особенно в разделе тарифов, и тоже думала, что это запросы...
Теперь буду писать промпты только на английском языке, а потом в переводчике на русский переводить, чтоб дешевле выходило. Спасибо!
1 ответ
по-моему, можно просить нейросети написать корректные промпты и сразу на нужном языке - так будет и быстрее, и практичнее)
Очень доступное объяснение! Теперь понятно, почему токены это не просто формальность, а реальный инструмент контроля бюджета и качества запросов в нейросетях