Проще, чем кажется: как сделать ИИ-кавер на любимую песню дома

Студийная запись кавера стоит денег, времени и нервов. Сделать ИИ-кавер — нет. Нейросети сравняли счет между профессионалами и теми, кто просто любит музыку и хочет экспериментировать дома. Порог входа упал до нуля, а качество — выросло до неприличия.
В этой статье расскажу, как пройти путь от чистого листа до готового трека: как работает технология RVC, где брать голосовые модели, как запустить процесс в Google Colab или на своем компьютере, обучить нейросеть на собственном голосе и избежать ошибок, которые портят звук у большинства новичков.
Домашняя студия все: почему сделать ИИ-кавер дома теперь быстрее и дешевле?
Путь к каверу всегда выглядел тяжеловесно: нужен был микрофон приличного уровня, акустически терпимая комната, аудиоинтерфейс, DAW (цифровая аудиостанция), плагины обработки и хотя бы базовое понимание записи вокала. Сейчас можно закрыть большую часть цепочки программно: очистка вокала делается через UVR5 (Ultimate Vocal Remover), преобразование голоса — через RVC, а финальная коррекция собирается из обычных эквалайзеров, компрессии и эффектов вроде реверберации.
Это стало возможным благодаря нейросетям нового поколения, и прежде всего — технологии RVC (Retrieval-based Voice Conversion), которая произвела настоящую революцию в мире домашнего аудиопродакшена. Порог входа снизился до нуля: хватает среднего ПК или даже бесплатного облачного сервиса вроде Google Colab. Что особенно важно — финансовые затраты стремятся к нулю. Большинство инструментов распространяется свободно, с открытым исходным кодом, и не требует подписок.
Почему именно сейчас? Тому несколько причин.
Во-первых, алгоритмы извлечения вокала из готового трека достигли качества, которое раньше было доступно только профессиональным студийным системам. Такие инструменты, как UVR5 (Ultimate Vocal Remover), умеют отделять вокальную дорожку от инструментальной практически без артефактов.
Во-вторых, голосовые модели для RVC перешли в публичный доступ: сообщества на Hugging Face и в Discord-серверах хранят тысячи готовых моделей голосов.
В-третьих, интерфейсы стали интуитивно понятными даже для тех, кто впервые открывает DAW (цифровую аудиостанцию).
От идеи до трека: как сделать ИИ-кавер на песню за четыре шага
Прежде чем углубляться в технические детали, полезно представить весь процесс как единую цепочку действий.
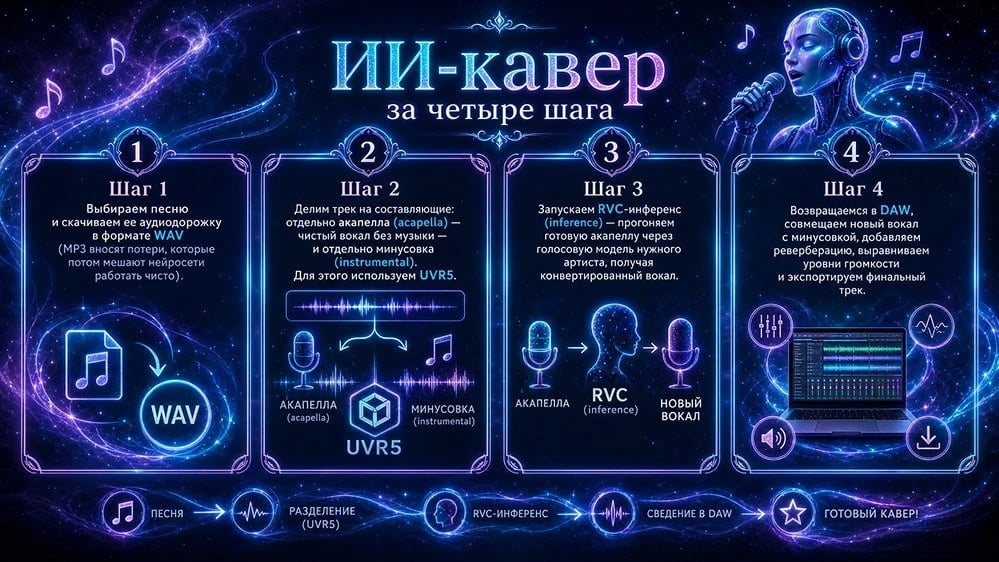
- На первом шаге я выбираю песню и скачиваю ее аудиодорожку в формате WAV — это принципиально важно, так как сжатые форматы вроде MP3 вносят потери, которые потом мешают нейросети работать чисто.
- На втором шаге я разделяю трек на составляющие: отдельно акапелла (acapella) — чистый вокал без музыки — и отдельно минусовка (instrumental). Для этого я использую UVR5.
- На третьем шаге я запускаю RVC-инференс (inference) — то есть прогоняю готовую акапеллу через голосовую модель нужного артиста, получая конвертированный вокал.
- И наконец, на четвертом шаге я возвращаюсь в DAW, совмещаю новый вокал с минусовкой, добавляю реверберацию, выравниваю уровни громкости и экспортирую финальный трек.
Каждый из этих шагов имеет свои нюансы, которые могут либо испортить результат, либо поднять его до действительно профессионального звучания. Разберем каждый из них детально.
Как подготовить материал, чтобы нейросеть выдала чистый результат
Качество результата на выходе напрямую зависит от качества материала на входе. Это железное правило, которое я усвоил на собственных ошибках. Если подать в RVC грязный, зашумленный вокал с реверберацией и эхом, на выходе получится каша из артефактов звука — металлические призвуки, дрожание, потеря разборчивости.
Первое, что нужно сделать — это скачать исходный трек в максимально высоком качестве. Формат WAV с частотой дискретизации не ниже 44 100 Гц — стандарт. Если файл доступен только в MP3, следует брать битрейт не менее 320 кбит/с. Никаких конвертаций из сжатого формата обратно в WAV — это не улучшает качество, а лишь раздувает размер файла.
Второй этап — разделение трека с помощью UVR5 (Ultimate Vocal Remover). Это бесплатное приложение с открытым кодом, которое использует сразу несколько архитектур нейросетей: MDX-Net, VR Architecture и Demucs. Я обычно сначала прогоняю трек через MDX-Net модель Kim Vocal 2 или MDX23C — они дают отличный результат на большинстве современных треков. Если остаются артефакты или «просачивается» инструментал, я запускаю второй проход через модель Reverb HQ для удаления реверберации из вокальной дорожки.
Очень важный момент: очистка вокала от реверберации — это отдельный обязательный шаг. Дело в том, что реверберация на акапелле «запутывает» алгоритм определения тональности (pitch) в RVC, что приводит к ошибкам конвертации и появлению неприятных металлических призвуков. Модели UVR5 справляются с этим хорошо, но иногда приходится делать два-три прохода, аккуратно выставляя параметры Overlap и Segment Size.
Еще один момент — шумоподавление. Если в вокальной дорожке остается фоновый шум, его можно убрать в Audacity, применив шумоподавление на уровне −40 дБ. После этого я нормализую уровень громкости акапеллы так, чтобы пики не превышали −1 дБ. Это важно: слишком тихий сигнал даст плохой инференс, слишком громкий — клиппинг и искажения.
Как сделать кавер песни с помощью ИИ: технология RVC от А до Я
Теперь перейдем к сердцу всего процесса. Именно RVC делает то, ради чего мы и затеяли весь этот процесс — меняет тембр голоса одного исполнителя на тембр другого, сохраняя при этом мелодику, ритм и артикуляцию оригинала.
RVC: что скрывается за аббревиатурой и как это меняет звук
RVC расшифровывается как Retrieval-based Voice Conversion — конверсия голоса на основе извлечения признаков. В отличие от классического синтеза речи или липсинка, RVC не генерирует звук «с нуля», а преобразует уже существующий вокал. Технически это работает так: нейросеть извлекает из входного аудиофайла лингвистический контент (фонемы, ритм, артикуляцию) и отдельно — характеристики тембра голоса источника, а затем переносит лингвистику на нейронные веса целевой голосовой модели.
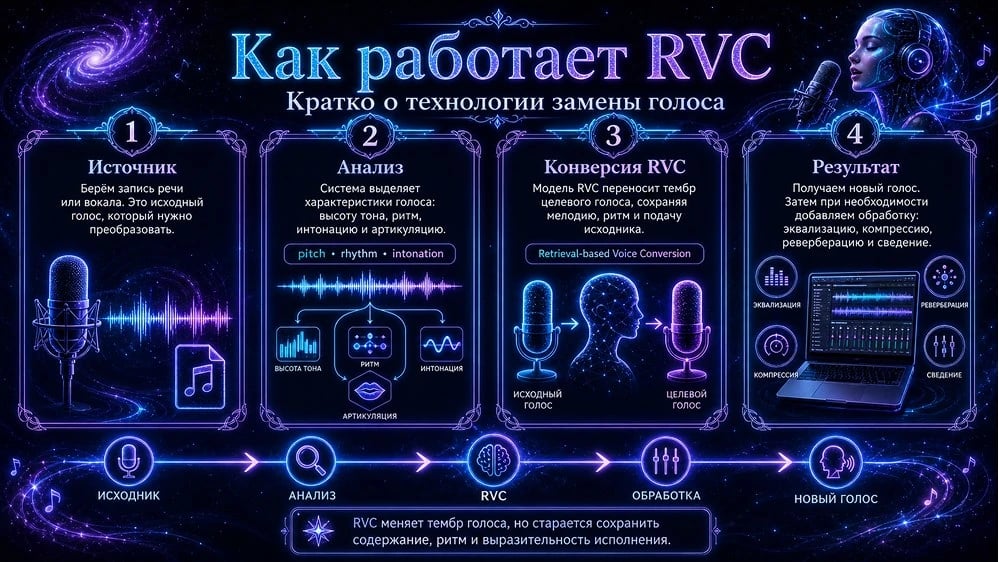
Что происходит под капотом? RVC использует несколько компонентов:
- Первый — это embedder-модель (обычно ContentVec), которая кодирует фонетическое содержимое вокала в числовые представления, по сути создавая «цифровой слепок» произношения.
- Второй компонент — это сама голосовая модель (файл с расширением .pth, содержащий нейронные веса), обученная на голосе конкретного артиста.
- Третий — индексная корзина (index file, файл .index), которая хранит «карту» характеристик тембра, формант и гармоник данного голоса, позволяя точнее воспроизводить уникальные черты звучания.
Понятие «форманты» здесь принципиально важно: это резонансные частоты голосового тракта, именно они создают неповторимость каждого голоса. RVC не просто меняет высоту звука — он переформирует весь спектр формант под голос целевой модели. Именно поэтому результат звучит убедительно, а не как просто ускоренная или замедленная запись.
Ключевой параметр при инференсе — транспозиция тональности (pitch shift). Если я конвертирую мужской вокал в женский голос, мне нужно сдвинуть тональность вверх на 12 полутонов (одна октава), и наоборот. Для голосов близкого диапазона достаточно коррекции в 0–5 полутонов. Неправильная транспозиция — одна из главных причин, почему AI-кавер звучит неестественно.
Банки голосов для RVC: Hugging Face и Discord-сервера
Голосовые модели для RVC — это готовые к использованию нейронные веса, обученные на голосе конкретного артиста. Их не нужно обучать самостоятельно (хотя это тоже возможно): огромные коллекции моделей уже лежат в открытом доступе.
Главные площадки для поиска моделей — это Hugging Face и специализированные Discord-серверы. На Hugging Face модели хранятся в виде репозиториев, их можно найти по запросу «rvc voice model» плюс имя исполнителя. Там же работают публичные Spaces — онлайн-демки, где можно протестировать модели без установки чего-либо на свой компьютер. Крупнейшим сообществом долгое время являлся Discord-сервер AI Hub, где участники делились моделями, датасетами и руководствами. После его реструктуризации основной архив переехал на сайт voice-models.com, где сегодня доступно более 27 000 уникальных моделей — от мировых поп-звезд до аниме-персонажей и исторических деятелей.
При выборе модели я обращаю внимание на несколько параметров: количество эпох (epochs) обучения (обычно качественная модель обучается 200–500 эпох), размер датасета (dataset), на котором она обучена, и частоту дискретизации модели (обычно 40 kHz или 48 kHz). Модели с пометкой RVC v2 предпочтительнее v1 — они дают более чистый результат и меньше артефактов.
Google Colab или локальная установка: гайд по созданию AI-кавера
Есть два принципиально разных подхода к запуску RVC, и выбор между ними зависит от ваших ресурсов.
Google Colab — это облачный сервис Google, который предоставляет бесплатный доступ к GPU прямо в браузере. Не нужно ничего устанавливать, не нужна видеокарта. Я просто открываю Colab-ноутбук (например, AICoverGen от SociallyIneptWeeb или RVC_TrainingV2 от ardha27), запускаю ячейки по порядку, загружаю акапеллу и модель — и получаю результат. Это идеальный вариант для новичка или для разового использования. Минус — Google периодически ограничивает время работы GPU на бесплатном тарифе, а при долгой работе сессия может оборваться. Платная подписка Colab Pro снимает большинство ограничений.
Локальная установка дает полный контроль и отсутствие ограничений по времени. Для нее нужна видеокарта NVIDIA с поддержкой CUDA (минимум 4 ГБ VRAM, оптимально — 8 ГБ и выше) и Python. Я работаю с форком Applio — это современный WebUI поверх RVC с удобным интерфейсом, встроенным UVR5 и расширенными настройками инференса. Установка занимает около 15 минут по официальному руководству.
Вот краткая пошаговая схема работы в Google Colab для создания AI-кавера:
- Открыть ноутбук AICoverGen в Google Colab по публичной ссылке.
- Подключить Google Drive для хранения файлов.
- Запустить установочные ячейки (займет 3–5 минут).
- Загрузить голосовую модель (.pth + .index) в папку модели.
- Загрузить акапеллу в формате WAV.
- Выставить параметры: тональность (pitch), метод определения высоты (рекомендую RMVPE), индексную ставку (0.6–0.75), защиту согласных (0.33).
- Запустить инференс и скачать результат.
Как сделать ИИ-кавер со своим голосом
Один из самых интересных сценариев — это когда я хочу не чужой голос «надеть» на чужую песню, а использовать свой собственный голос как основу. Иными словами, я пою треки сам, а затем конвертирую их в голос любимого исполнителя. Или, напротив, хочу создать собственную голосовую модель на базе своего голоса.
Для создания собственной голосовой модели мне потребуется датасет — набор чистых аудиозаписей своего голоса общей длительностью от 5 до 30 минут. Важно, чтобы это было чистое пение или речь без фоновых шумов, музыки и эха. Записывать лучше всего в комнате с хорошей акустической обработкой, через конденсаторный микрофон. После записи я прогоняю материал через UVR5 для удаления остаточного шума и реверберации, нарезаю на фрагменты по 5–15 секунд и сохраняю в формате WAV с частотой дискретизации 44 100 Гц.
Процесс обучения модели в RVC (через Colab или локально) занимает от 30 минут до нескольких часов в зависимости от объема датасета и мощности GPU. Ключевые параметры обучения: количество эпох (для небольшого датасета достаточно 150–300 эпох, для большого — до 500), batch size (обычно 4–8), а также выбор частоты дискретизации модели (40 kHz — стандарт, 48 kHz — для более высокого качества). После завершения обучения система сохраняет нейронные веса в файл .pth и формирует индексную корзину (index file) — оба файла необходимы для последующего инференса.
Когда модель моего голоса готова, я использую ее точно так же, как любую другую модель из банка голосов: загружаю акапеллу любимой песни, прогоняю через свою модель и получаю трек, где я пою чужой хит — пусть и в несколько «улучшенной» версии себя, с более ровным тембром и точным интонированием.
Сведение ИИ-кавера: как добиться естественного звучания без артефактов
Получить конвертированный вокал из RVC — это еще не конец работы. Сырой выход инференса почти всегда звучит немного «механически» и выбивается из контекста минусовки. Чтобы кавер звучал как готовый трек, а не как демо-набросок, нужно провести сведение.
Я работаю в DAW — это может быть Reaper, FL Studio, Ableton, Audacity или любая другая цифровая аудиостанция. Процесс сведения AI-кавера включает несколько этапов.
- Первый — выравнивание по времени. Конвертированный вокал иногда чуть сдвигается относительно оригинала. Я загружаю минусовку и конвертированный вокал на отдельные дорожки и визуально выравниваю их по пикам — обычно достаточно сдвинуть вокальную дорожку на несколько миллисекунд.
- Второй — эквализация. Конвертированный голос из RVC нередко имеет избыточные частоты в диапазоне 2–5 кГц, что создает ощущение «резкости». Я срезаю лишнее через параметрический EQ, параллельно подчеркивая «воздух» выше 12 кГц для естественности.
- Третий — компрессия. Уровень громкости конвертированного вокала может неравномерно «дышать» на разных участках. Мягкий компрессор с ratio 3:1 и attack 10–20 мс выравнивает динамику и делает пение более плотным.
- Четвертый — реверберация. Это критически важный шаг. Поскольку мы добавляли чистую, «сухую» акапеллу, конвертированный вокал звучит в «вакууме». Я добавляю реверберацию через плагин обработки — обычно короткий помещений (room) или плейт-реверб с pre-delay 15–20 мс и временем затухания 1–1.5 секунды. Задача — воссоздать акустическое пространство, близкое к оригинальному треку, чтобы вокал «сросся» с минусовкой. Параллельно добавляю небольшой chorus или гармонайзер для того, чтобы добавить гармоники и сделать звук «живее».
- Пятый — финальный микс. Я выравниваю баланс между вокалом и инструменталом, при необходимости автоматизирую громкость вокала на особо тихих или громких участках и экспортирую финальный трек в формате WAV 24 bit / 44 100 Гц.
Почему ваш AI-кавер звучит плохо: разбираем типичные ошибки
За время работы с RVC я набил немало шишек. Вот самые распространенные ошибки, которые я наблюдаю у себя и у других.
Неправильно выставленная тональность (pitch)
Если конвертированный голос звучит слишком тонко или слишком низко, причина именно в этом. Решение: подбирать транспозицию поэтапно, шагами по 1–2 полутона, ориентируясь на естественный диапазон голосовой модели. Мужские модели обычно работают в диапазоне ±5 полутонов без потери качества, при более крупных сдвигах нарастают артефакты.
Высокое значение индексной ставки (Search Feature Ratio) при «грязной» индексной корзине
Если датасет, на котором обучалась модель, содержал фоновый шум или музыку, то высокое значение индекса (0.9–1.0) буквально «вкачивает» этот шум в результат. Я рекомендую начинать с 0.5 и повышать постепенно.
Подача зашумленной акапеллы без предварительной очистки
Металлические призвуки, «роботизация» голоса и потеря разборчивости на 80% случаев объясняются именно этим. UVR5 с двойным проходом решает проблему.
Неправильный выбор алгоритма определения тональности
Стандартный pm работает медленно и часто ошибается на сложных мелодических переходах. RMVPE — оптимальный выбор для большинства случаев, для очень чистых женских голосов хорошо работает Crepe.
Игнорирование параметра Split Audio
Если этот параметр выключен, длинные треки могут давать неравномерный уровень громкости: одни участки — тихие, другие — громкие. Включение Split Audio решает эту проблему, разбивая аудио на отрезки и обрабатывая их по одному.
Ошибка на этапе сведения
Многие забывают убрать реверберацию из акапеллы перед инференсом, а потом добавляют новую реверберацию при сведении. В итоге получается двойная реверберация, которая «размазывает» звук и делает его неразборчивым. Вывод: сначала чистим вокал до «сухого» состояния, потом добавляем пространство уже в DAW.
RVC, SVC, онлайн-сервисы: сравниваем методы создания AI-каверов
Далее представлю подробное сравнение несколько принципиально разных подходов к созданию ИИ-кавера.
| Метод | Качество | Сложность | Стоимость | Контроль над результатом | Требования к железу |
|---|---|---|---|---|---|
| RVC (локально) | Отличное | Средняя | Бесплатно | Максимальный | GPU NVIDIA, 8+ ГБ VRAM |
| RVC (Google Colab) | Хорошее | Низкая | Бесплатно / от $10/мес (Pro) | Высокий | Только браузер |
| SVC (So-VITS-SVC) | Хорошее | Высокая | Бесплатно | Высокий | GPU, Python-опыт |
| Voicify.ai | Среднее | Очень низкая | От $14/мес | Минимальный | Только браузер |
| Kits.AI | Среднее | Очень низкая | Freemium | Минимальный | Только браузер |
| Musicfy | Среднее | Очень низкая | Freemium | Низкий | Только браузер |
| MVSEP + RVC | Хорошее | Средняя | Бесплатно (MVSEP) | Средний | GPU для RVC |
RVC остается золотым стандартом для всех, кто серьезно занимается AI-каверами. Главное преимущество — огромная экосистема готовых голосовых моделей, активное сообщество и постоянное развитие. Если я хочу получить действительно убедительный результат, который можно выложить в интернет, — это мой выбор.
SVC (So-VITS-SVC) — альтернативная архитектура конверсии голоса, которая в ряде случаев дает более «мягкое» и музыкальное звучание, особенно на длинных нотах. Однако порог входа выше: настройка требует больше технических знаний, а скорость инференса ниже. SVC исторически был популярен в азиатских сообществах, особенно для воспроизведения голосов аниме-персонажей и японских исполнителей.
Онлайн-сервисы — это вариант для тех, кто хочет быстро получить результат без технических сложностей. Voicify.ai, Kits.AI, Musicfy и аналогичные платформы предлагают готовые голосовые модели и интерфейс типа «загрузи песню — выбери голос — скачай». Минусы: ограниченная библиотека голосов, водяные знаки на бесплатных версиях, меньший контроль над параметрами и вопросы конфиденциальности (файлы загружаются на чужие серверы).
Мой совет: для первого знакомства использовать Google Colab — он не требует установки и позволяет сразу «потрогать» процесс. Когда появится понимание и желание двигаться дальше — переходить на локальную установку Applio. Онлайн-сервисы оставить для случаев, когда нужно сделать что-то быстро и без претензий на высокое качество.
FAQ
Нужна ли мне мощная видеокарта, чтобы сделать ИИ-кавер?
Для инференса через Google Colab — нет, видеокарта не нужна вообще: вся вычислительная мощность предоставляется облаком. Для локальной установки RVC или Applio видеокарта NVIDIA с поддержкой CUDA значительно ускоряет работу, однако существует режим работы через CPU — он медленнее раза в три-четыре, но принципиально позволяет запустить процесс даже на ноутбуке без дискретной графики.
Можно ли сделать ИИ-кавер, не умея петь?
Да, и это один из главных плюсов технологии. RVC работает с уже существующими вокальными дорожками — я просто «переодеваю» голос оригинального исполнителя.
Сколько времени занимает весь процесс от начала до конца?
После первого знакомства с инструментами полный цикл от скачивания трека до готового кавера у меня занимает 20–40 минут. Разделение вокала в UVR5 — 3–5 минут, инференс в RVC — 2–10 минут в зависимости от длины трека и мощности GPU, сведение в DAW — 10–20 минут. Первый раз может занять несколько часов из-за установки, изучения интерфейса и экспериментов с настройками — это нормально.
Легально ли создавать AI-каверы с чужими голосами?
Правовой статус AI-каверов находится в «серой зоне» и продолжает формироваться. Использование голосовой модели известного артиста в некоммерческих и личных целях в большинстве юрисдикций не преследуется. Однако публикация и тем более монетизация таких треков может нарушать авторские права на оригинальную запись и права исполнителя.
Рекомендую внимательно изучать правила платформ (YouTube, Spotify, TikTok), на которые планируется загружать материал, и избегать коммерческого использования без соответствующих разрешений.
Почему конвертированный голос звучит «металлически» или «роботизированно»?
Это классические артефакты звука, которые возникают из-за грязной акапеллы на входе (не убрали реверберацию или фоновый шум), неправильной транспозиции тональности, слишком высокого значения индексной ставки при «грязной» индексной корзине, или использование устаревшего алгоритма определения pitch.
Решение — тщательная очистка вокала через UVR5, переход на алгоритм RMVPE и постепенная настройка параметров инференса: снизить индексную ставку до 0.5–0.6 и попробовать разные значения транспозиции.
Весь процесс, как сделать ИИ-кавер, который я описал в этой статье, укладывается в несколько десятков минут и требует лишь базового понимания того, как устроена цепочка: акапелла — инференс — сведение. Если вы только начинаете путь, стартуйте с Google Colab и готовых моделей с Hugging Face — это самый быстрый способ увидеть результат своими глазами и почувствовать, насколько мощным инструментом стал RVC.

Комментарии к статье
А можно у ИИ просить кавер в определенном стиле? Обычно всегда одинаковые треки получаются
А можно гайд, как записать трек с нуля? Уже давно хочу попробовать, но не знаю с чего начать
Да и вообще, тема очень интересная. В последнее время ии-треки бьют все чарты. Надо бы тоже научиться)
а как быть с авторскими правами, если захочется выложить кавер в TikTok или Reels?